 目录
目录JAVA全系列 教程
3762个小节阅读:7088.1k
目录


C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

整合Spring Cloud Sleuth其实没什么的难的,在这之前需要准备以下三个服务:
三个服务的调用关系如下图:
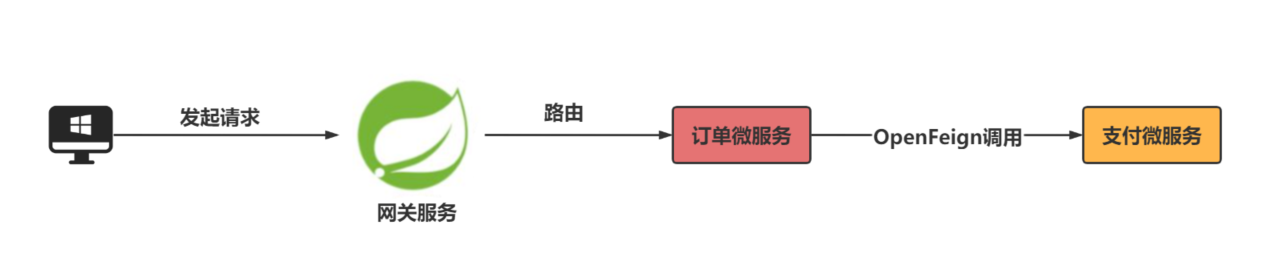
流程:
客户端请求网关发起订单的请求,网关路由给订单服务,订单服务调用支付服务进行支付。
第一步,我们需要将 Sleuth 的依赖项添加到三个微服务的 pom.xml文件
xxxxxxxxxx<!-- Sleuth依赖项 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>第⼆步,我们打开微服务模块的 application.yml 配置⽂件,在配置⽂件中添加采样率和每秒 采样记录条数。
xxxxxxxxxxspring: sleuth: sampler: # 采样率的概率,100%采样 probability: 1.0 # 每秒采样数字最⾼为100 rate: 1000注意:
在配置文件里设置了⼀个 probability,它应该是⼀个 0 到 1 的浮点 数,用来表示采样率。我这⾥设置的 probability 是 1,就表示对请求进⾏ 100% 采样。如果 我们把 probability 设置成⼩于 1 的数,就说明有的请求不会被采样。如果⼀个请求未被采 样,那么它将不会被调⽤链追踪系统 Track 起来。
由于sleuth并没有UI界面,因此需要调整一下日志级别才能在控制台看到更加详细的链路信息。在三个服务的配置文件中添加以下配置:
xxxxxxxxxx## 设置openFeign和sleuth的日志级别为debug,方便查看日志信息logging:level:org.springframework.cloud.openfeign: debugorg.springframework.cloud.sleuth: debug
http://localhost:9527/order/index
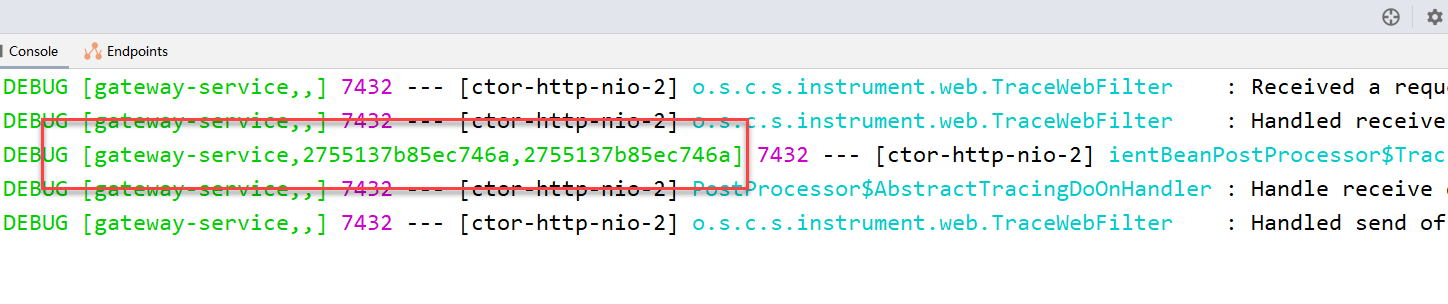
日志格式中总共有四个参数,含义分别如下:
- 第一个:服务名称
- 第二个:traceId,唯一标识一条链路
- 第三个:spanId,链路中的基本工作单元id