 目录
目录JAVA全系列 教程
3762个小节阅读:7095.4k
目录


C语言快速入门
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
在硬件层面,大部分的计算机硬件都会用缓存来提高速度,比如 CPU 会有多级缓存,RAID 卡也有读写缓存。而在软件层面,我们用的数据库就是一个缓存设计非常好的例子。在 SQL 语句的优化、索引设计以及磁盘读写的各个地方,都有缓存。
缓存两个原则
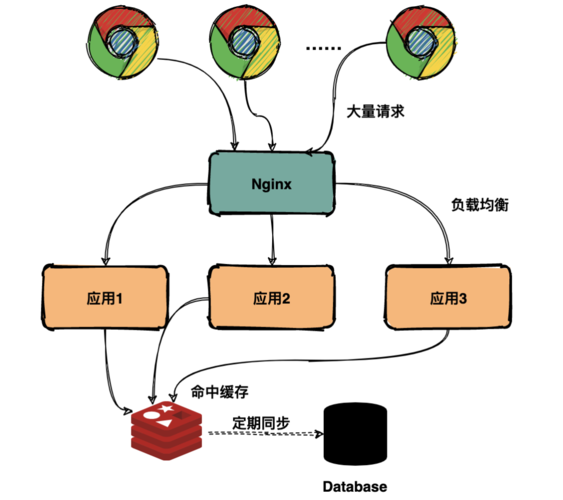
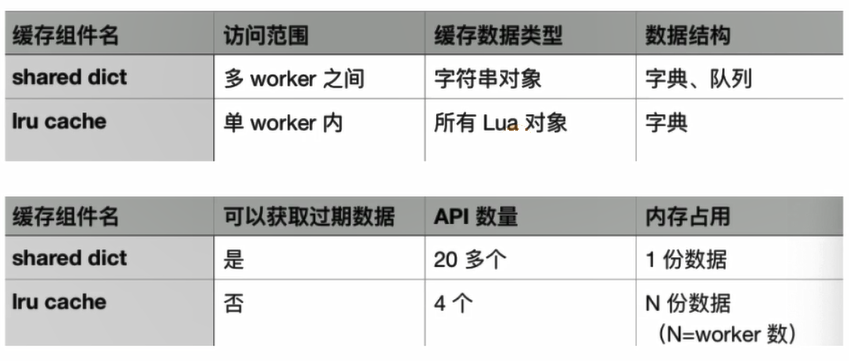
OpenResty 中有两个缓存的组件:shared dict 缓存和 lru 缓存。前者只能缓存字符串对象,缓存的数据有且只有一份,每一个 worker 都可以进行访问,所以常用于 worker 之间的数据通信。后者则可以缓存所有的 Lua 对象,但只能在单个 worker 进程内访问,有多少个 worker,就会有多少份缓存数据。
第一个问题,缓存数据的序列化。由于共享字典中只能缓存字符串对象,所以,如果你想要缓存数组,就少不了要在 set 的时候要做一次序列化,在 get 的时候做一次反序列化:
xxxxxxxxxxresty --shdict='dogs 1m' -e 'local dict = ngx.shared.dogsdict:set("Tom", require("cjson").encode({a=111}))print(require("cjson").decode(dict:get("Tom")).a)'
lru 缓存的接口只有 5 个:new、set、get、delete 和 flush_all。和上面问题相关的就只有 get 接口,让我们先来了解下这个接口是如何使用的:
xxxxxxxxxxresty -e 'local lrucache = require "resty.lrucache"local cache, err = lrucache.new(200)cache:set("dog", 32, 0.01)ngx.sleep(0.02)local data, stale_data = cache:get("dog")print(stale_data)'