 目录
目录大数据全系列 教程
1869个小节阅读:467.3k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night


Flink on Yarn模式的原理是依靠YARN来调度Flink任务,目前在企业中使用较多。这种模式的好处是可以充分利用集群资源,提高集群机器的利用率,并且只需要1套Hadoop集群,就可以执行MapReduce和Spark任务,还可以执行Flink任务等,操作非常方便,不需要维护多套集群,运维方面也很轻松。Flink on Yarn模式需要依赖Hadoop集群,并且Hadoop的版本需要是2.2及以上。我们的课程里面选择的Hadoop版本是3.1.3。
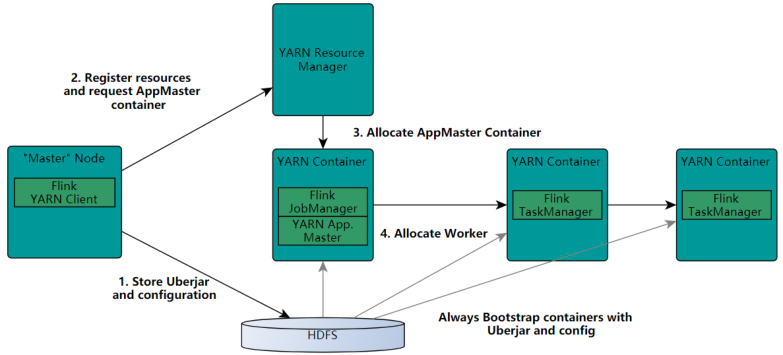
客户端Client上传jar包和配置文件到HDFS集群上
Client向ResourceManager提交应用并申请资源,ResourceManager在NodeManager上启动容器,运行AppMaster。
ResourceManager分配Container资源并启动AppMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager;
ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager(多个)。
TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务;
总结:
JobManager进程和TaskManager进程都由 Yarn的NodeManager监控;JobManager和TaskManager都是运行NodeManager的容器(Contanier)中.实时效果反馈
1. 以下选项中关于FlinkOnYarn集群架构的描述错误的是?
A JobManager运行ResourceManager容器Contanier中。
B TaskManager运行NodeManager容器Contanier中。
C JobManager进程和TaskManager进程都由 Yarn的NodeManager监控。
2. 以下选项中关于FlinkOnYarn集群架构的描述错误的是?
A 如果JobManager进程异常退出,则 ResourceManager会重新调度JobManager到其他机器。
B 同一个作业的 JobManager和AppMaster运行在两个不同的Container容器中。
C 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager。
答案:
1=>A 运行NodeManager容器Contanier中。
2=>B 二者运行在同一个容器中。