 目录
目录大数据全系列 教程
1869个小节阅读:467k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

SparkStreaming+Kafka 版本整合方式有两种模式,一种是Receiver模式,另一种是Direct模式。
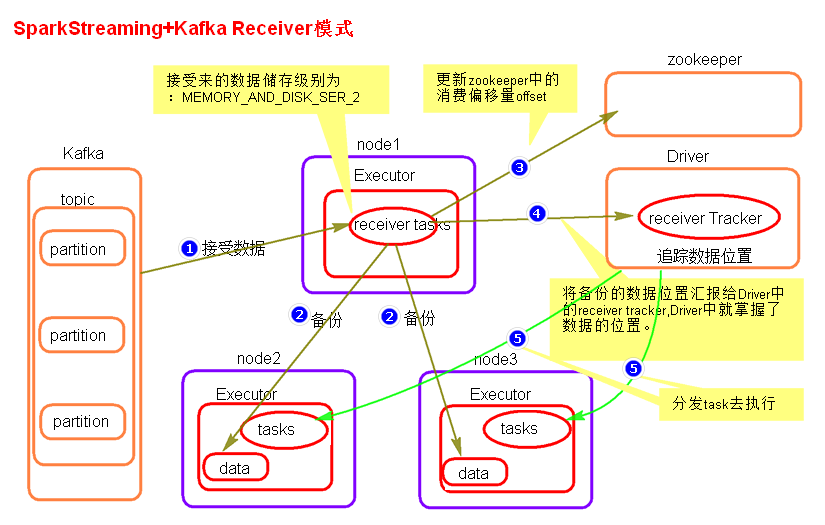
Receiver模式原理图(已经过时,了解即可)
Direct模式原理图
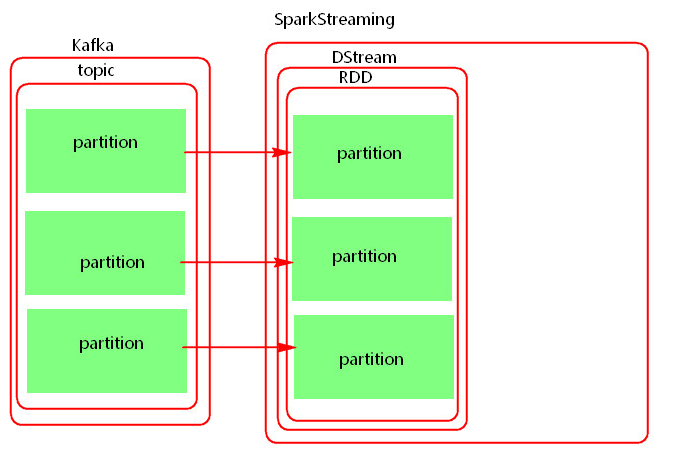
Driect模式就是将kafka看成存数据的一方,这种模式没有采用Receiver接收器模式,而是采用直连的方式,不是被动接收数据,而是主动去取数据,在处理每批次时会根据offset位置向Kafka中获取数据。
消费者偏移量也不是用zookeeper来管理,而是使用Spark自己进行消费者偏移量的维护,如果没有设置checkpoint机制,消费偏移量默认是存在内存中,如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。
Direct模式底层读取Kafka数据实现是Simple Consumer api实现,这种api提供了从每批次数据中获取offset的接口,所以对于精准消费数据的场景,可以使用Direct 模式手动维护offset方式来实现数据精准消费。
Direct模式并行度设置
Direct模式的并行度与当前读取的topic的partition个数一致,所以Direct模式并行度由读取的kafka中topic的partition数决定的。
实时效果反馈
1. 关于SparkStreaming整合Kafka的Direct模式的描述,错误的是:
A Driect模式就是将kafka看成存数据的一方,这种模式没有采用Receiver接收器模 式,而是采用直连的方式。
B Driect模式中Spark不是被动接收数据,而是主动去取数据,在处理每批次时会根 据offset位置向Kafka中获取数据。
C 消费者偏移量也不是用zookeeper来管理,而是使用Spark自己进行消费者偏移量 的维护,如果没有设置checkpoint机制,消费偏移量默认是存在内存中,如果设置了 checkpoint目录,那么消费偏移量也会保存在checkpoint中。
D SparkStreaming整合Kafka的Receiver模式比Direct模式更好用,更流行。
答案:
1=>D