目录
目录大数据全系列 教程
1869个小节阅读:467.9k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
##1.4 Hive架构
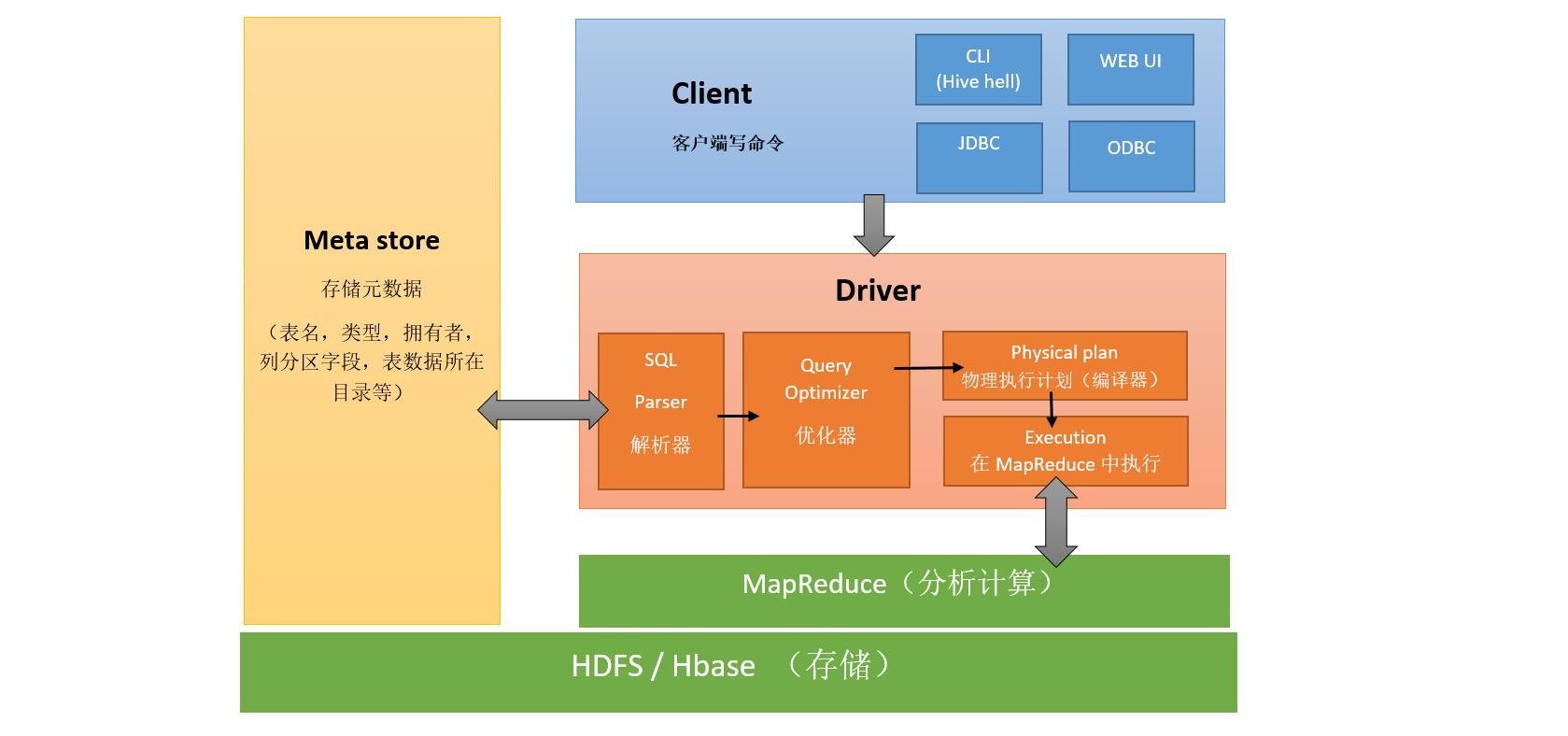
• Hive的架构
(1)用户接口主要有三个:CLI,JDBC/ODBC和 WebUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby(hive自带的内存数据库)。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
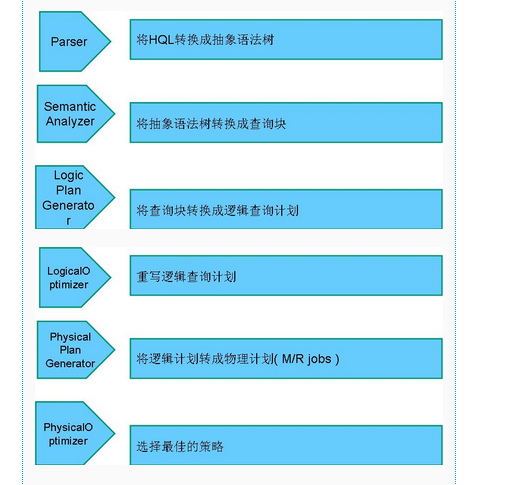
(3)解释器(SQL Parser)、编译器(Compiler)、优化器(Optimizer)完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有执行器(Executor)调用MapReduce执行。
解释器:将HQL字符串转换为抽象语法树AST,通过使用第三方工作完成,比较antlr;对AST进行语法分析,比如表是否存在、字段是否存在、HQL语义是否存在错误等。
编译器:将AST编译生成逻辑执行计划。
优化器:对逻辑执行计划进行优化。
执行器:把优化后的逻辑执行计划转换成可以运行的物理计划。对于HIve来说就是MR/Spark。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
比如:select id,name from psn;
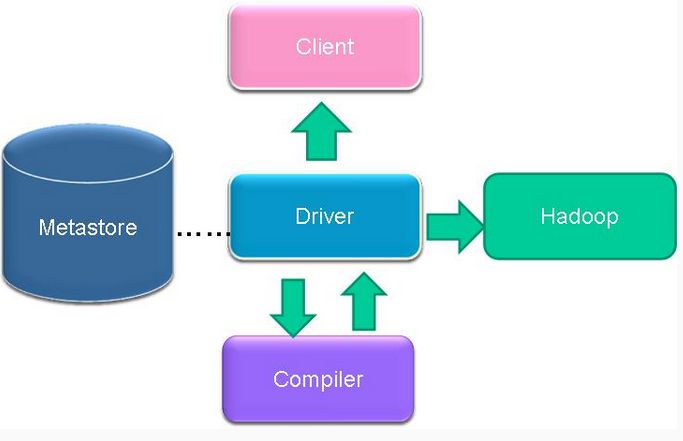
• Hive的架构
编译器将一个Hive SQL转换操作符
操作符是Hive的最小的处理单元
每个操作符代表HDFS的一个操作或者一道MapReduce作业
• Operator(操作符)
Operator都是hive定义的一个处理过程
Operator都定义有:
protected List <Operator<? extends Serializable >> childOperators; protected List <Operator<? extends Serializable >> parentOperators; protected boolean done; // 初始化值为false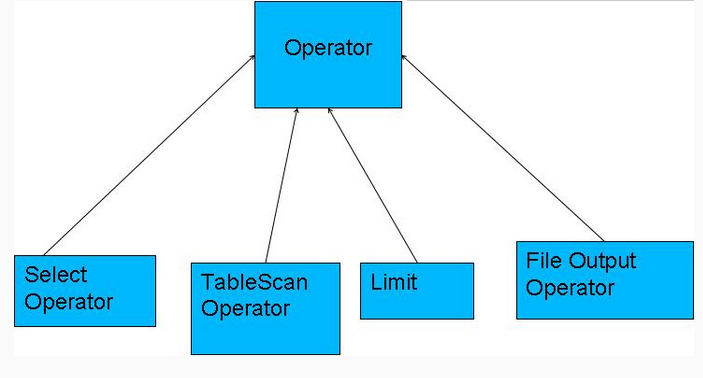
查询操作 表扫描操作 限制输出 文件输出操作。
ANTLR词法语法分析工具解析hql