 目录
目录大数据全系列 教程
1869个小节阅读:465.7k


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
###5.4.12 collector.init方法
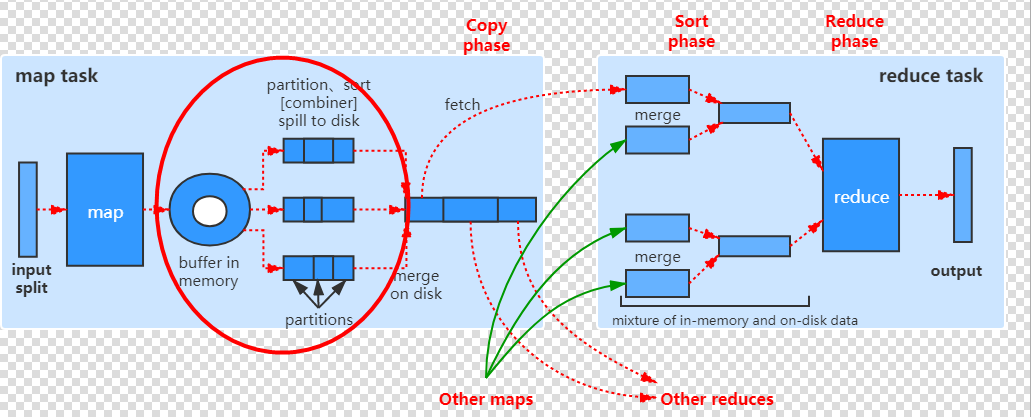
点击MapTask类中的createSortingCollector()->单击collector.init(context);
xxxxxxxxxxpublic interface MapOutputCollector<K, V> { public void init(Context context ) throws IOException, ClassNotFoundException;}选中init方法,Ctrl+Alt+B->选择MapOutputBuffer类:
xxxxxxxxxxpublic void init(MapOutputCollector.Context context ) throws IOException, ClassNotFoundException { job = context.getJobConf(); reporter = context.getReporter(); mapTask = context.getMapTask(); mapOutputFile = mapTask.getMapOutputFile(); sortPhase = mapTask.getSortPhase(); spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS); //获取分区的数量也就是reduce的数量 partitions = job.getNumReduceTasks(); rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks 阈值默认 0.8 //MAP_SORT_SPILL_PERCENT = "mapreduce.map.sort.spill.percent" final float spillper = job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8); //圆形缓冲区的大小100MB //IO_SORT_MB = "mapreduce.task.io.sort.mb" //DEFAULT_IO_SORT_MB = 100; final int sortmb = job.getInt(MRJobConfig.IO_SORT_MB, MRJobConfig.DEFAULT_IO_SORT_MB); indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT, INDEX_CACHE_MEMORY_LIMIT_DEFAULT); if (spillper > (float)1.0 || spillper <= (float)0.0) { throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT + "\": " + spillper); } if ((sortmb & 0x7FF) != sortmb) { throw new IOException( "Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb); } //MAP_SORT_CLASS = "map.sort.class" 如果配置了该参数对应的类,则使用它进行排序 //如果没有设置过,使用默认的QuickSort(快排) sorter = ReflectionUtils.newInstance(job.getClass( MRJobConfig.MAP_SORT_CLASS, QuickSort.class, IndexedSorter.class), job); // buffers and accounting 100变为二进制,然后向左位移20, int maxMemUsage = sortmb << 20; maxMemUsage -= maxMemUsage % METASIZE; //定义一个字节数组,存放圆形缓冲区中的(k,v,p)对 //圆形缓冲区本质上是默认长度为100MB一个字节数组,通过一定的算法实现逻辑上的圆形缓存区的效果。 kvbuffer = new byte[maxMemUsage]; bufvoid = kvbuffer.length; kvmeta = ByteBuffer.wrap(kvbuffer) .order(ByteOrder.nativeOrder()) .asIntBuffer(); setEquator(0); bufstart = bufend = bufindex = equator; kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA; softLimit = (int)(kvbuffer.length * spillper); bufferRemaining = softLimit; LOG.info(JobContext.IO_SORT_MB + ": " + sortmb); LOG.info("soft limit at " + softLimit); LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid); LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization 排序比较器 comparator = job.getOutputKeyComparator(); //mapper类输出key的类型 keyClass = (Class<K>)job.getMapOutputKeyClass(); //mapper类输出value的类型 valClass = (Class<V>)job.getMapOutputValueClass(); serializationFactory = new SerializationFactory(job); keySerializer = serializationFactory.getSerializer(keyClass); keySerializer.open(bb); valSerializer = serializationFactory.getSerializer(valClass); valSerializer.open(bb);
// output counters 计算器 字节数、记录数等 mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES); mapOutputRecordCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS); fileOutputByteCounter = reporter .getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// compression 压缩处理 if (job.getCompressMapOutput()) { Class<? extends CompressionCodec> codecClass = job.getMapOutputCompressorClass(DefaultCodec.class); codec = ReflectionUtils.newInstance(codecClass, job); } else { codec = null; }
// combiner 类相关 final Counters.Counter combineInputCounter = reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS); combinerRunner = CombinerRunner.create(job, getTaskID(), combineInputCounter, reporter, null); if (combinerRunner != null) { final Counters.Counter combineOutputCounter = reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS); combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job); } else { combineCollector = null; } spillInProgress = false; //MAP_COMBINE_MIN_SPILLS = "mapreduce.map.combine.minspills" //如果配置文件中配置了就使用配置的值,没有配置默认为3个。 minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3); //启动一个名称为SpillThread守护线程,进行写溢出文件 spillThread.setDaemon(true); spillThread.setName("SpillThread"); spillLock.lock(); try { //启动线程 spillThread.start(); while (!spillThreadRunning) { spillDone.await(); } } catch (InterruptedException e) { throw new IOException("Spill thread failed to initialize", e); } finally { spillLock.unlock(); } if (sortSpillException != null) { throw new IOException("Spill thread failed to initialize", sortSpillException); } }