 目录
目录大数据全系列 教程
1869个小节阅读:465.3k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

在Flink1.14版本文档中没有提供:

我们参考Flink1.13版文档:
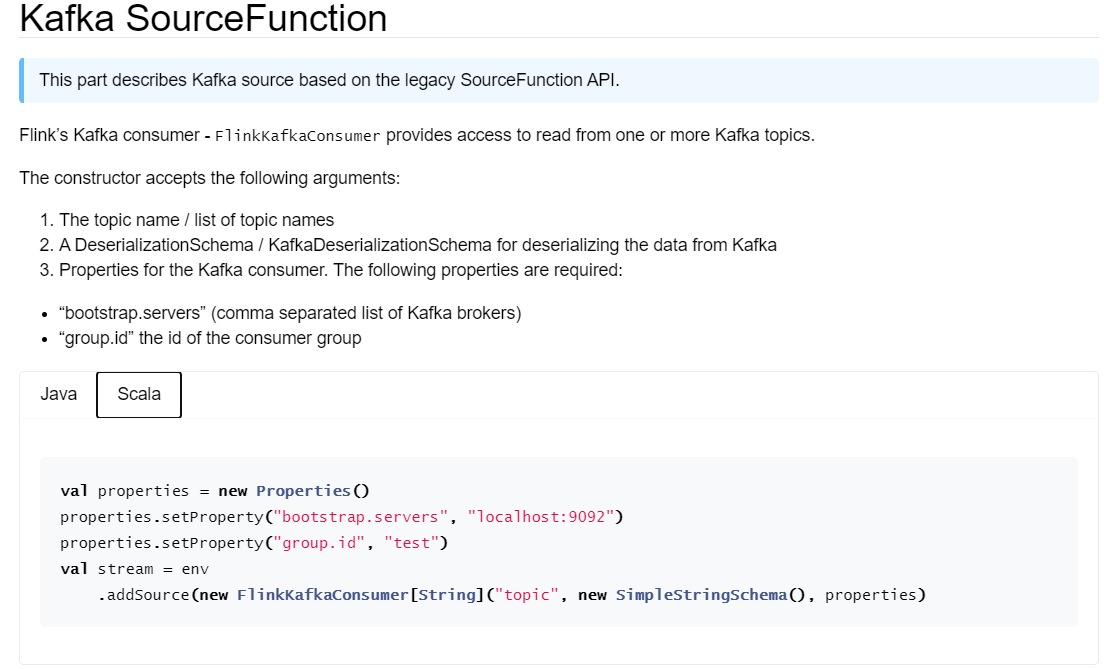
FlinkKafkaConsumer参数描述:
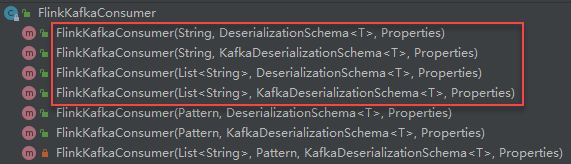
订阅的主题:topic,一个Topic名称或一个列表(多个Topic)
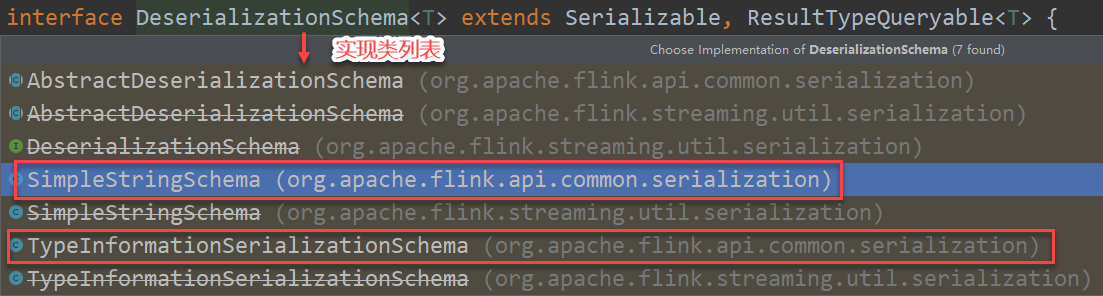
反序列化规则:DeserializationSchema / KafkaDeserializationSchema

消费者属性:
"bootstrap.servers" -> "node1:9092,node2:9092,node3:9092"group.id当从Kafka消费数据时,需要指定反序列化实现类:将Kafka读取二进制数据,转换为String对象。
xxxxxxxxxxpackage com.itbaizhan.flink.scala.source
import org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.kafka.common.serialization.StringDeserializer
import java.util.Properties
object FlinkKafkaConsumerDemo { def main(args: Array[String]): Unit = { //构建环境对象 val env = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 推荐设置主题的分区相同 env.setParallelism(3) //kafka参数配置 val prop = new Properties() //设置brokers地址 prop.setProperty("bootstrap.servers","node2:9092,node3:9092,node4:9092") //设置消费者组 prop.setProperty("group.id","flinkgroup1") //添加隐式转换 import org.apache.flink.streaming.api.scala._ //读取kafka中的数据 val dataDS: DataStream[String] = env.addSource( new FlinkKafkaConsumer[String]("flink-topic1", new SimpleStringSchema(), prop)) //输出 //dataDS.print() dataDS.flatMap(_.split("\\s+")) .map((_,1)) .keyBy(_._1) .sum(1) .print() //触发执行 env.execute("FlinkKafkaConsumerDemo") }}