 目录
目录大数据全系列 教程
1869个小节阅读:464.9k


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

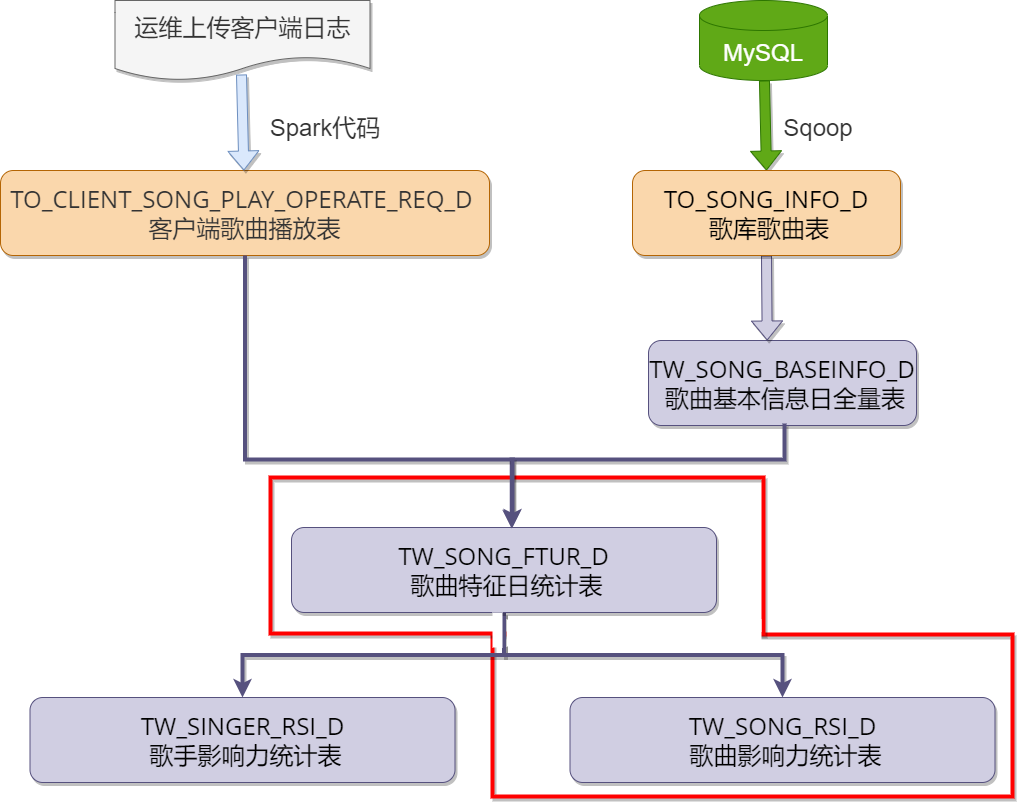
创建类:com.itbaizhan.scala.musicproject.dm.content.GenerateTmSongRsiD.scala
判断参数是否合法
xxxxxxxxxxdef main(args: Array[String]): Unit = { if(args.length < 1) { println(s"请输入数据日期,格式例如:年月日(20301011)") System.exit(1) } //后续代码..}根据是否本地运行,构造SparkSession对象
xxxxxxxxxxif(ConfigUtils.LOCAL_RUN){ sparkSession = SparkSession.builder().master("local") .appName("Generate_TM_Song_Rsi_D") .config("spark.sql.shuffle.partitions","1") .config("hive.metastore.uris",ConfigUtils.HIVE_METASTORE_URIS) .enableHiveSupport() .getOrCreate() sparkSession.sparkContext.setLogLevel("Error")}else{ sparkSession = SparkSession.builder() .appName("Generate_TM_Song_Rsi_D") .enableHiveSupport().getOrCreate()}定义常量,接收日期
xxxxxxxxxx//输入数据的日期 ,格式 :年月日 yyyymmddval currentDate = args(0)切换Hive的命名空间
xxxxxxxxxxsparkSession.sql(s"use ${ConfigUtils.HIVE_DATABASE}")将表TW_SONG_FTUR_D中当天的数据转化为DataFrame对象
xxxxxxxxxx//将tw_song_ftur_d的指定日期的数据读取后转化为DataFrame对象val dataFrame: DataFrame = sparkSession.sql( s""" |select data_dt,--日期 | nbr,--歌曲id | name,--歌曲名称 | sing_cnt,--歌曲当日点唱数 | supp_cnt,--歌曲当日点赞数 | rct_7_sing_cnt,--歌曲近7日点唱数 | rct_7_supp_cnt,--歌曲近7日点赞数 | rct_7_top_sing_cnt,--歌曲近7日最高点唱数 | rct_7_top_supp_cnt,--歌曲近7日最高点赞数 | rct_30_sing_cnt,--歌曲近30日点唱数 | rct_30_supp_cnt,--歌曲近30日点赞数 | rct_30_top_sing_cnt,--歌曲近30日最高点唱数 | rct_30_top_supp_cnt--歌曲近30日最高点赞数 |from tw_song_ftur_d |where data_dt = ${currentDate} |""".stripMargin)导入隐式转换
xxxxxxxxxximport org.apache.spark.sql.functions._为dataFrame对象添加经过公式计算得到的1、7、30日影响力,并注册为临时视图
xxxxxxxxxx//为dataFrame对象添加进过计算得到的3个列:1、7、30日歌曲影响力dataFrame.withColumn("rsi_1d",pow(log(col("sing_cnt")/1+1)*0.63*0.8 +log(col("supp_cnt")/1+1)*0.63*0.2,2)*10) .withColumn("rsi_7d",pow( (log(col("rct_7_sing_cnt")/7+1)*0.63+log(col("rct_7_top_sing_cnt")+1)*0.37)*0.8 + (log(col("rct_7_supp_cnt")/7+1)*0.63+log(col("rct_7_top_supp_cnt")+1)*0.37)*0.2, 2)*10) .withColumn("rsi_30d",pow( (log(col("rct_30_sing_cnt")/7+1)*0.63+log(col("rct_30_top_sing_cnt")+1)*0.37)*0.8 + (log(col("rct_30_supp_cnt")/7+1)*0.63+log(col("rct_30_top_supp_cnt")+1)*0.37)*0.2, 2)*10) //并注册为临时视图 .createTempView("temp_tw_song_ftur_d")分别从临时视图TEMP_TW_SONG_FTUR_D中获取1、7、30日影响力对应的DataFrame对象
xxxxxxxxxx//从临时视图temp_tw_song_ftur_d中分别获取1、7、30日歌曲影响力对应的DataFrame对象val rsi_1d = sparkSession.sql( s""" |select "1" as period,nbr,name,rsi_1d as rsi, | row_number() over(partition by data_dt order by rsi_1d desc) as rsi_rank |from temp_tw_song_ftur_d |""".stripMargin)val rsi_7d = sparkSession.sql( s""" |select "7" as period,nbr,name,rsi_7d as rsi, | row_number() over(partition by data_dt order by rsi_7d desc) as rsi_rank |from temp_tw_song_ftur_d |""".stripMargin)val rsi_30d = sparkSession.sql( s""" |select "30" as period,nbr,name,rsi_30d as rsi, | row_number() over(partition by data_dt order by rsi_30d desc) as rsi_rank |from temp_tw_song_ftur_d |""".stripMargin)取三者的并集后注册临时视图
xxxxxxxxxx//将以上三个DataFrame对象做并集处理,并注册临时视图resultrsi_1d.union(rsi_7d).union(rsi_30d).createTempView("result")将临时视图result中的数据保存到Hive的表TW_SONG_RSI_D中
xxxxxxxxxx//将临时视图result中的数据保存到Hive中baizhan_music.tw_song_rsi_dsparkSession.sql( s""" |insert overwrite table tw_song_rsi_d |partition(data_dt=${currentDate}) select * from result |""".stripMargin)将临时视图result中的数据排名前30的数据保存到MySQL的表tm_song_rsi中
xxxxxxxxxx//为MySQL创建属性对象val prop: Properties = new Properties()prop.setProperty("user",ConfigUtils.MYSQL_USER)prop.setProperty("password",ConfigUtils.MYSQL_PASSWORD)prop.setProperty("driver","com.mysql.jdbc.Driver")//将临时视图result中的数据保存到MySQL中songresult.tm_song_rsi(排名前30的)sparkSession.sql( s""" |select ${currentDate} as data_dt,period,nbr,name,rsi,rsi_rank from result where rsi_rank <=30 |""".stripMargin).write.mode(SaveMode.Overwrite) .jdbc(ConfigUtils.MYSQL_URL,"tm_song_rsi",prop)println("=====all finished====")