 目录
目录大数据全系列 教程
1869个小节阅读:467.1k


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
##2.5 直连数据库式启动和使用
启动hadoop集群,在node1上执行startha.sh,如果有namenode没有启动起来,只需要在对应的节点上执行命令:hdfs --daemon start namenode
在node2上启动hive:
xxxxxxxxxx[root@node2 ~]# hive使用hive,创建表:
xxxxxxxxxxhive> show databases;OKdefaultTime taken: 0.923 seconds, Fetched: 1 row(s)hive> show tables;OKTime taken: 0.081 secondshive> create table tb_test(id int);OKTime taken: 1.001 secondshive> show tables;OKtb_testTime taken: 0.087 seconds, Fetched: 1 row(s)hive> create table test(id int,age int);OKTime taken: 0.123 secondshive> show tables;OKtb_testtest
访问active的namenode,查看文件列表
http://node2:9870/explorer.html#/user/hive/warehouse
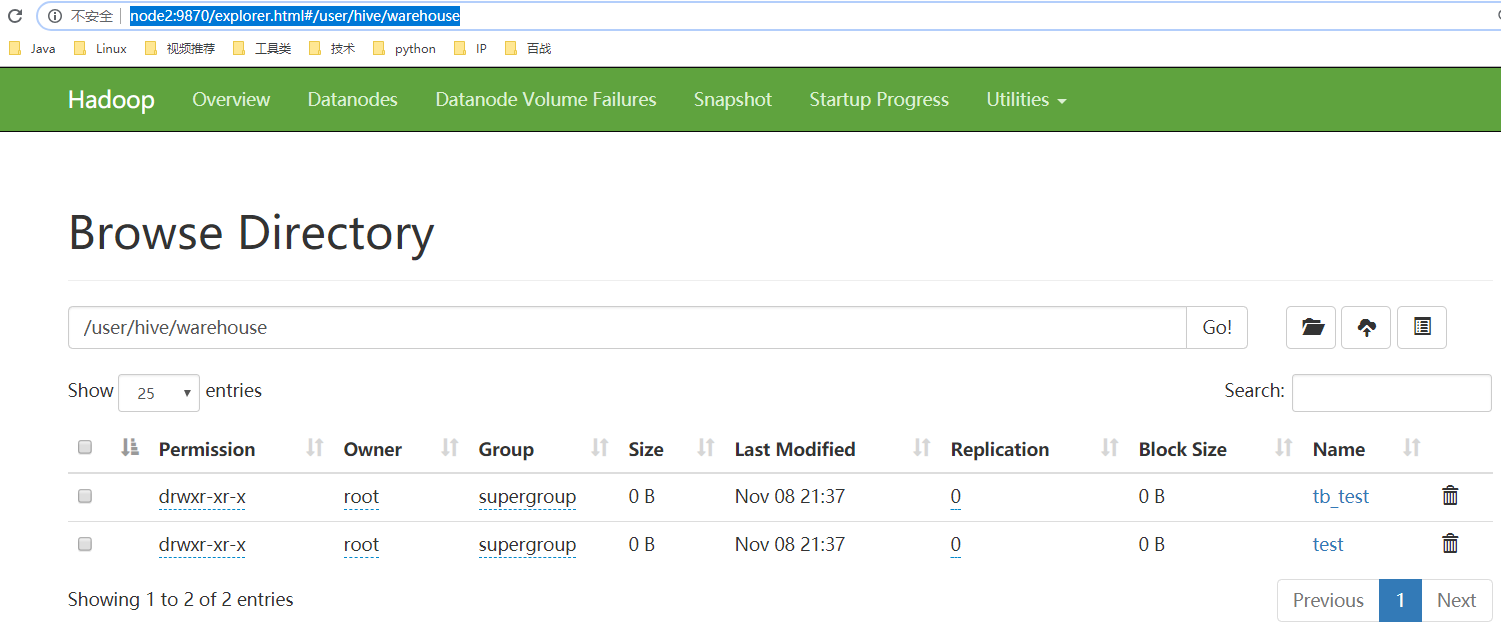
表在hdfs也有对应的目录,但是目录下没有数据。
向test表插入数据
xxxxxxxxxxhive> insert into test values(1,1);Query ID = root_20211108214257_de79649c-530d-4420-9236-d8514d3d8928Total jobs = 3Launching Job 1 out of 3Number of reduce tasks determined at compile time: 1查看Yarn的web页面:
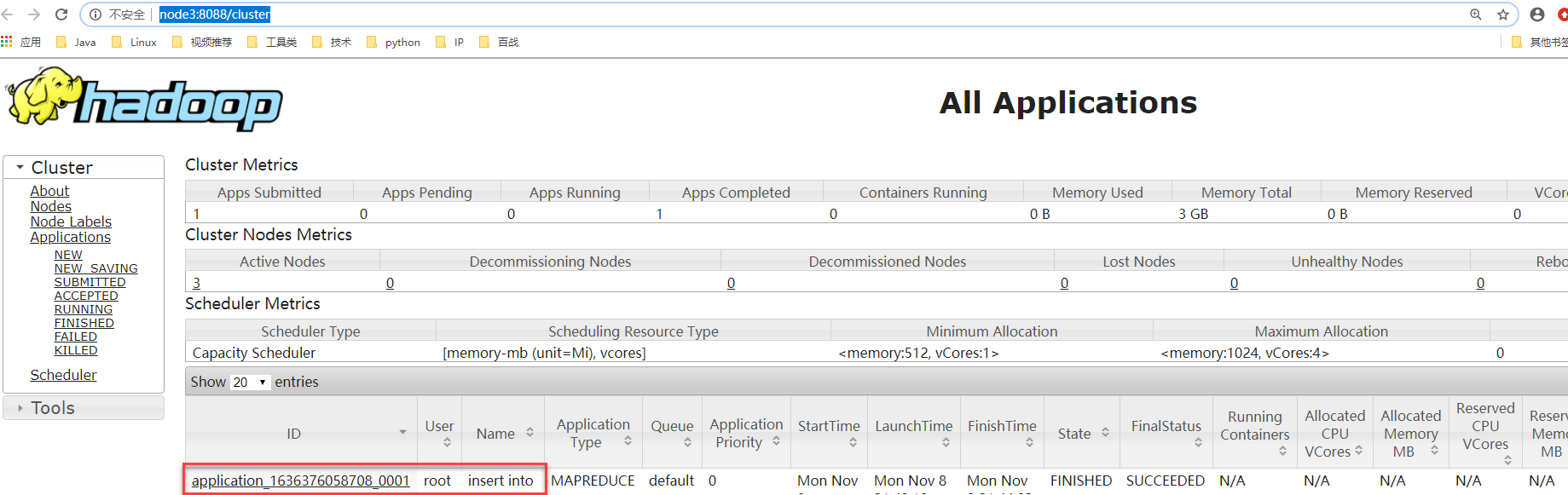
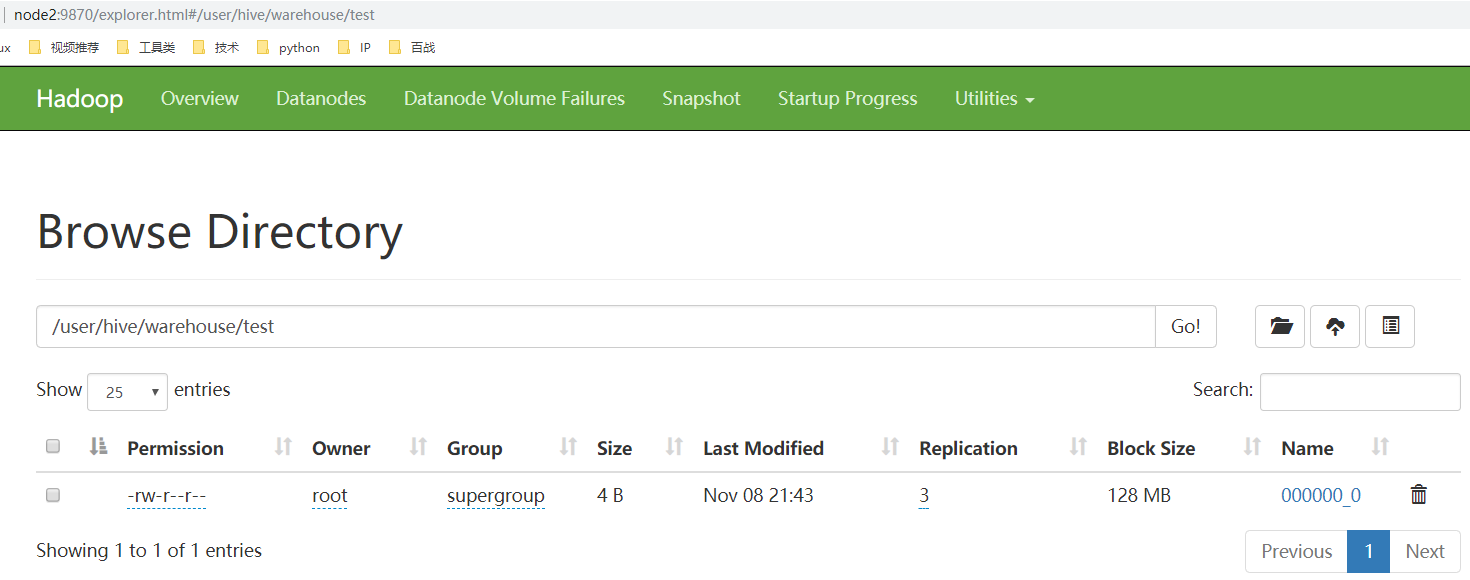
当任务执行完之后,再查看HDFS的文件列表页面,在test目录下多出文件。
在node1中连接上mysql查看表中的数据
xxxxxxxxxx[root@node1 ~]# mysql -uroot -p123456mysql> use hive;Database changedmysql> show tables;+-------------------------------+| Tables_in_hive |+-------------------------------+......| COLUMNS_V2 | 保存表中列的数据......| DBS | 保存的是数据库实例......| TBLS | 保存的表数据......
查看DBS表中的数据:
xxxxxxxxxxmysql> select * from DBS;+-------+-----------------------+--------------------------------------+---------+------------+------------+-----------+| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME |+-------+-----------------------+--------------------------------------+---------+------------+------------+-----------+| 1 | Default Hive database | hdfs://mycluster/user/hive/warehouse | default | public | ROLE | hive |
查看TBLS表中数据:
xxxxxxxxxxmysql> select * from TBLS;+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED |+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+| 1 | 1636378648 | 1 | 0 | root | USER | 0 | 1 | tb_test | MANAGED_TABLE | NULL | NULL | || 2 | 1636378679 | 1 | 0 | root | USER | 0 | 2 | test | MANAGED_TABLE | NULL | NULL | |+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
查看表 COLUMNS_V2中的数据:
xxxxxxxxxxmysql> select * from COLUMNS_V2;#表id 描述 列名 类型 顺序+-------+---------+-------------+-----------+-------------+| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |+-------+---------+-------------+-----------+-------------+| 1 | NULL | id | int | 0 || 2 | NULL | age | int | 1 || 2 | NULL | id | int | 0 |+-------+---------+-------------+-----------+-------------+
在node2上hive中查看表中的数据:
xxxxxxxxxxhive> select * from tb_test;OKTime taken: 0.443 secondshive> select * from test;OK1 1Time taken: 0.281 seconds, Fetched: 1 row(s)
注意:目前的这种配置方式,是将hive的服务器端和客户端放在一台服务器上(node2)。如果想通过jdbc程序访问该hive是没有办法的,这是因为hive没有开启hiveserver2服务。
思考:hive是如何连接到hdfs的?