 目录
目录大数据全系列 教程
1869个小节阅读:467.3k


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

在车辆分布情况分析的模块中,我们把所有数据的车牌号car都存在了窗口计算的状态里,在窗口收集数据的过程中,状态会不断增大。一般情况下,只要不超出内存的承受范围,这种做法也没什么问题;但如果我们遇到的数据量很大呢?
把所有数据暂存放到内存里,显然不是一个好注意。我们会想到,可以利用redis这种内存级k-v数据库,为我们做一个缓存。但如果我们遇到的情况非常极端,数据大到惊人呢?比如上千万级,亿级的卡口车辆数据呢?(假设)要去重计算。
如果放到redis中,假设有6千万车牌号(每个10-20字节左右的话)可能需要几G的空间来存储。当然放到redis中,用集群进行扩展也不是不可以,但明显代价太大了。
一个更好的想法是,其实我们不需要完整地存车辆的信息,只要知道他在不在就行了。所以其实我们可以进行压缩处理,用一位(bit)就可以表示一个车辆的状态。这个思想的具体实现就是布隆过滤器(Bloom Filter)。
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
它本身是一个很长的二进制向量,既然是二进制的向量,那么显而易见的,存放的不是0,就是1。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少。我们的目标就是,利用某种方法(一般是Hash函数)把每个数据,对应到一个位图的某一位上去;如果数据存在,那一位就是1,不存在则为0。
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
下面是一个简单的 Bloom filter 结构,开始时集合内没有元素:

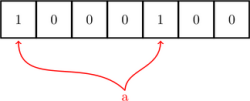
当来了一个元素 a,进行判断,这里需要一个(或者多个)哈希函数然后二进制运算(模运算),计算出对应的比特位上为 0 ,即是 a 不在集合内,将 a 添加进去:
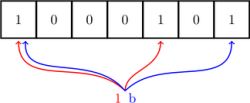
之后的元素,要判断是不是在集合内,也是同 a 一样的方法,只有对元素哈希后对应位置上都是 1 才认为这个元素在集合内(虽然这样可能会误判):
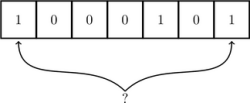
随着元素的插入,Bloom filter 中修改的值变多,出现误判的几率也随之变大,当新来一个元素时,满足其在集合内的条件,即所有对应位都是 1 ,这样就可能有两种情况,一是这个元素就在集合内,没有发生误判;还有一种情况就是发生误判,出现了哈希碰撞,这个元素本不在集合内。
本项目中可以采用google 提供的BoolmFilter进行位图计算和判断:
xxxxxxxxxxBloomFilter.create[String]( Funnels.stringFunnel(Charset.forName("UTF-8")), 100000)Funnels.stringFunnel()指的是将对String类型的数据使用布隆过滤器。这里我们使每个区域都对应一个布隆过滤器,位长度为100000,经过测试,可以对100万左右的数量进行去重判断,每个布隆过滤器可以认为相当于一个数组,大概占用空间为100K。
xxxxxxxxxx<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>21.0</version></dependency>代码实现:
xxxxxxxxxxpackage com.itbaizhan.traffic.distribution
import com.google.common.hash.{BloomFilter, Funnels}import com.itbaizhan.traffic.util.TrafficLogimport org.apache.commons.lang3.time.FastDateFormatimport org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}import org.apache.flink.api.common.functions.AggregateFunctionimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.connector.kafka.source.KafkaSourceimport org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializerimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindowsimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.util.Collector
import java.nio.charset.Charsetimport java.time.Duration
object CarAreaDistributionBloomFilter { def main(args: Array[String]): Unit = { //TODO 1.从kafka读取日志数据 val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //导入隐式转换 import org.apache.flink.streaming.api.scala._ //设置并行度 推荐设置主题的分区相同 streamEnv.setParallelism(1) //构建KafkaSource对象 val kafkaSource: KafkaSource[String] = KafkaSource.builder[String]() //设置kafka brokers .setBootstrapServers("node2:9092,node3:9092,node4:9092") //设置消费的主题 .setTopics("traffic-topic") //设置消费者组 .setGroupId("gp7") //设置消费偏移量:latest .setStartingOffsets(OffsetsInitializer.latest()) //设置返序列化类 .setValueOnlyDeserializer(new SimpleStringSchema()) .build() //设置kafka数据源 val dataDS : DataStream[String] = streamEnv.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),//暂不设置水位线 "KafkaSource") //处理非法数据和设置按照事件时间进行处理 val trafficLogDS: DataStream[TrafficLog] = dataDS.filter(_.split(",").length == 7) //数据类型转换 .map(line => { val arrs = line.split(",") TrafficLog(arrs(0).toLong, arrs(1), arrs(2), arrs(3), arrs(4).toDouble, arrs(5), arrs(6)) }) .assignTimestampsAndWatermarks( //数据出现乱序,一般不超过2秒 WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2)) //从日志数据对象中,提取事件时间列 .withTimestampAssigner(new SerializableTimestampAssigner[TrafficLog] { override def extractTimestamp(element: TrafficLog, recordTimestamp: Long): Long = { //返回值必须是Long行 element.actionTime } }) ) //按照区域进行分组 val keyedStream: KeyedStream[TrafficLog, String] = trafficLogDS.keyBy(_.areaId)
//TODO 存储 区域 - 车辆数 map val map = scala.collection.mutable.Map[String,BloomFilter[String]]()
//每隔5秒统计最近1分钟(测试10秒)时间内整个城市中每个区分布多少量车 keyedStream.window(SlidingProcessingTimeWindows.of( Time.seconds(10),Time.seconds(5))) //apply 全量函数 ,process:全量函数,aggregate 既有增量,也有全量 .aggregate(new AggregateFunction[TrafficLog,Long,Long] { //初始化值 override def createAccumulator(): Long = 0L
override def add(value: TrafficLog, accumulator: Long): Long = { //判断前Map中是否包含 area_id if(map.contains(value.areaId)){ //如果包含当前区域,获取当前key对应的数值, //并判断车辆车牌是否重复, val bool: Boolean = map.get(value.areaId).get.mightContain(value.car) if(!bool){//如果不包含,就加1 //将当前车辆设置到布隆过滤器中 map.get(value.areaId).get.put(value.car) accumulator + 1L }else{ accumulator } }else{//如果map不包含当前 area_id //为当前区域构建一个BloomFilter对象 val bloomFilter: BloomFilter[String] = BloomFilter.create[String]( Funnels.stringFunnel(Charset.forName("UTF-8")), 100000) //将当前车牌保存 bloomFilter.put(value.car) //将bloomFilter保存到map中 map.put(value.areaId,bloomFilter)
//返回1 accumulator+ 1L } } //获取 override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a+b },new WindowFunction[Long,String,String,TimeWindow]{ //定义时间转化类 private val fdf: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss") override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[String]): Unit = { //获取窗口的开始时间 val startTime:String = this.fdf.format(window.getStart) //获取窗口的结束时间 val endTIme:String = this.fdf.format(window.getEnd) out.collect(s"开始时间:${startTime} - 结束时间:${endTIme},区域ID:${key},车辆总数 = ${input.last}") } }) .print()
streamEnv.execute("车辆分布情况") }}