 目录
目录大数据全系列 教程
1869个小节阅读:465.2k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
hadoop为基本的数据类型提供的对应的序列化和反序列化功能的类。如下图所示:
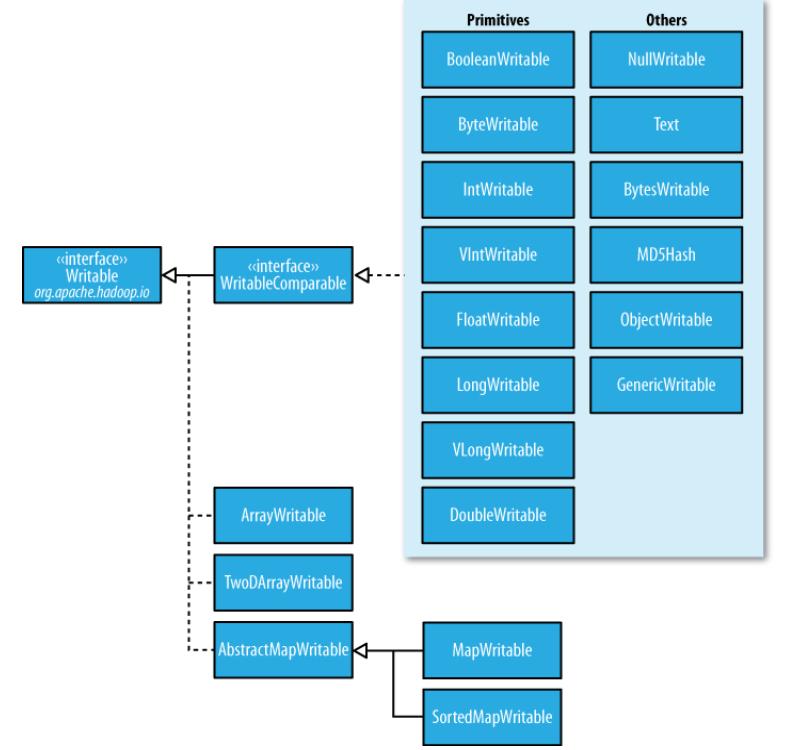
| Java类型 | Hadoop Writable类型 |
|---|---|
| Byte | ByteWritable |
| Int | IntWritable |
| Long | LongWritable |
| Float | FloatWritable |
| Double | DoubleWritable |
| Boolean | BooleanWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
有些时候这些基本的类不能满足我们的开发需求,需要自定义类,那么这些自定义的类如何实现序列化和反序列化呢?
具体实现的步骤如下:
实现Writable接口
预置一个空的构造函数,这是因为在发序列化时会被调用的
xxxxxxxxxxpublic Xxx(){super();}
重写序列化的方法
xxxxxxxxxx@Overridepublic void write(DataOutput out) throws IOException{ out.writeInt(age); out.writeLong(xx); ....}重写反序列化的方法
xxxxxxxxxx@Overridepublic void readFields(DataInput in) throws IOException{ age = in.readInt(); xx = in.readLong(); ....}顺序一定要保持一致,先序列化的谁,一定要先反序列化谁。
重写类的toString()方法
如果该类需要作为Mapper的key中使用,还需要实现Comparable接口,这是因为Shuffle过程中需要对Mapper的key做排序。