 目录
目录大数据全系列 教程
1869个小节阅读:467.2k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
在大数据整个生产过程中,需要先对数据进行数据清洗,将杂乱无章的数据整理为符合后面处理要求的规整数据。
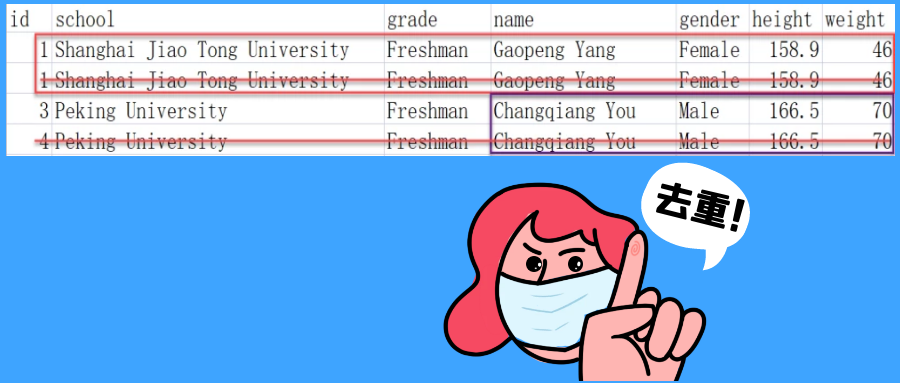
去重方法 dropDuplicates
功能∶对DataFrame的数据进行去重,如果重复数据有多条,取第一条
xxxxxxxxxx//去重,无参数是对数据进行整体去重df.dropDuplicates().show()//同样可以针对字段进行去重,如下传入'col1','col2'字段,表示这两个列的值一样就认为你是重复数据df.dropDuplicates("col1","col2").show()代码实操:
xxxxxxxxxxpackage com.itbaizhan.sqlimport org.apache.spark.SparkConfimport org.apache.spark.sql.{Column, DataFrame, SparkSession}object SSDropDuplicates { def main(args: Array[String]): Unit = { //1.创建配置文件对象 val conf: SparkConf = new SparkConf() .setMaster("local[*]") .setAppName("SSDropDuplicates") //2.创建SparkSession对象 val spark: SparkSession = SparkSession.builder() .config(conf).getOrCreate() //4.读取本地csv文件,返回DataFrame对象 val df: DataFrame = spark.read.format("csv") //第一行为列名 .option("header", true) //设置字段之间的分隔符,默认是“,” .option("delimiter", ",") //未设置前各个字段都是String类型,设置后匹配对应的类型 .option("inferSchema","true") .option("encoding", "utf-8") .load("data/sql/clear_data.csv") df.printSchema() df.show() println("---------无参数去重---------") //5,无参数去重,将所有列联合起来进行比较,只保留一条(第一条) df.dropDuplicates().show() //6.有参数去重,指定字段进行去重 println("---------指定字段进行去重---------") df.dropDuplicates("name","gender", "height","weight").show()
//3.关闭spark spark.stop() }}实时效果反馈
1. 以下关于去重API描述的选项中正确的是?
A df.dropDuplicates()无参数对全部的列联合起来进行比较, 去除重复值, 只保留最先出现 的一条。
B `df.dropDuplicates()无参数对全部的列联合起来进行比较, 去除重复值, 只保留中间出现 一条。
C `df.dropDuplicates()无参数对全部的列联合起来进行比较, 去除重复值, 只保留最后出现 一条。
答案:
1=>A。