 目录
目录大数据全系列 教程
1869个小节阅读:467.8k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
###5.4.11 圆形缓冲区引入
如果有reduce任务,通过NewOutputCollector写到圆形缓冲区中。所以自定义Mapper类在执行context.write(xx)方法时调用的就是NewOutputCollector类中的write方法:
xxxxxxxxxx@Overridepublic void write(K key, V value) throws IOException, InterruptedException { //将(key,value,partitin)缩写(k,v,p) collector.collect(key, value, partitioner.getPartition(key, value, partitions));}放回到构造方法中:
xxxxxxxxxxNewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf job, TaskUmbilicalProtocol umbilical, TaskReporter reporter ) throws IOException, ClassNotFoundException { //涉及到后续的圆形缓冲区,稍后讲: collector = createSortingCollector(job, reporter); ......}点击createSortingCollector方法:
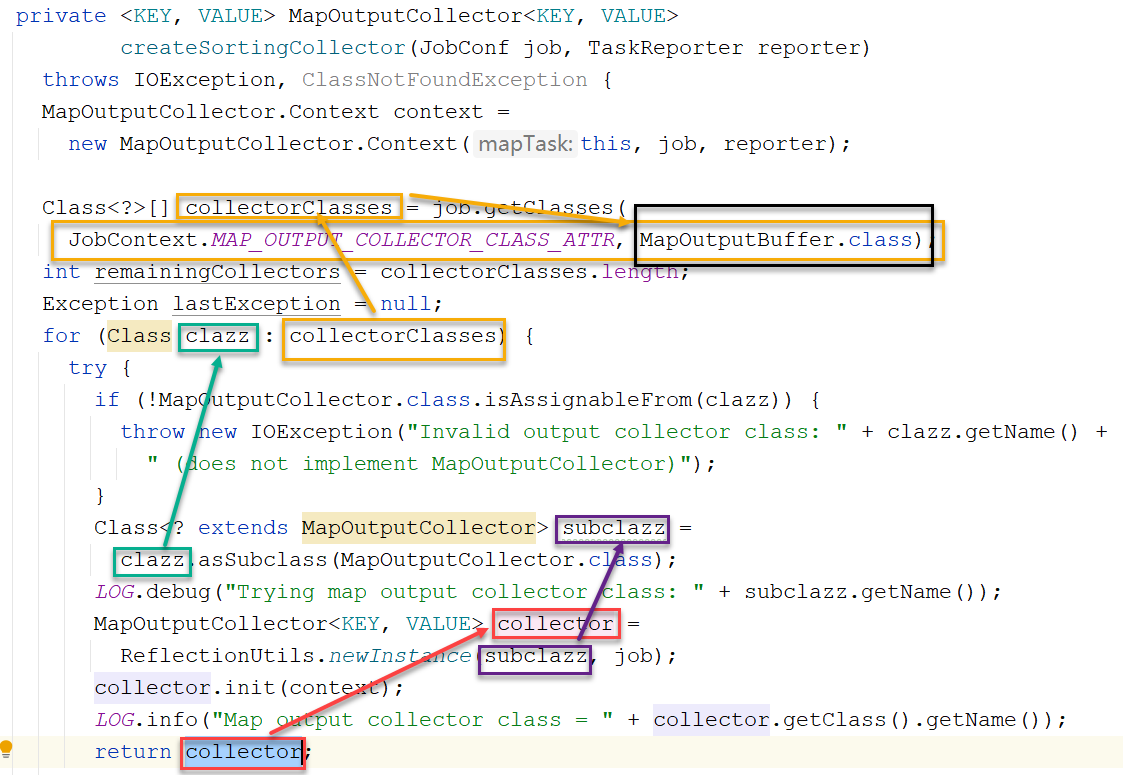
所以该collector就是找MAP_OUTPUT_COLLECTOR_CLASS_ATTR对应的配置的类,如果没有配置则使用默认的MapOutputBuffer类来创建对象。MapOutputBuffer就是圆形缓冲区的类。