 目录
目录大数据全系列 教程
1869个小节阅读:465.3k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
##七、HBase优化面试题
问题1:预分区(PreCreating Regions)的好处是什么?
参考答案:可以加快批量写入速度的方法是通过预先创建一些空的region,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。提高了并发插入数据的能力。
问题2:如何设定Region的预分区?
参考答案:
手动设定预分区
xxxxxxxxxxhbase> create 'table1','info',SPLITS => ['10000','20000','30000','40000'] 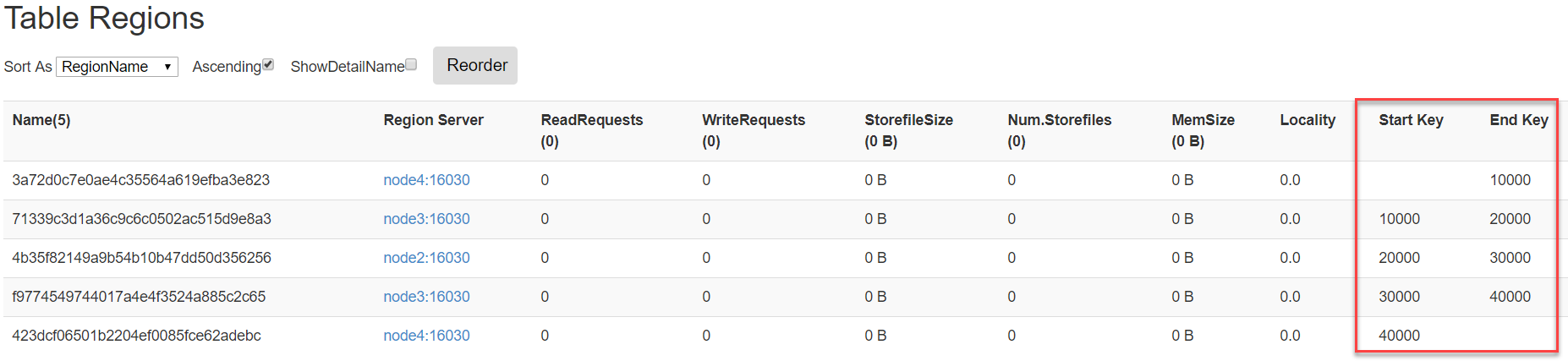
生成16进制序列预分区
xxxxxxxxxxcreate 'table2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} 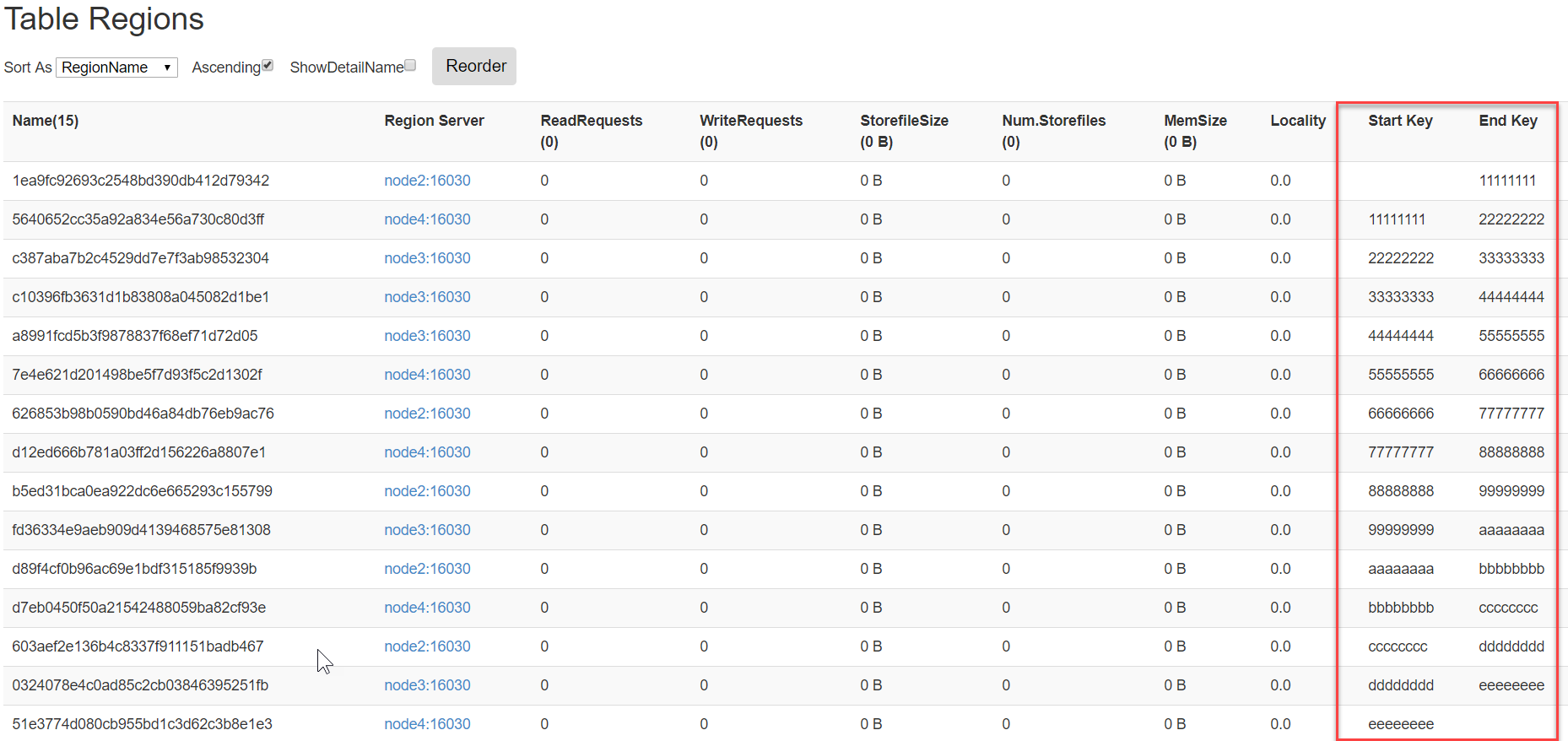
按照文件中设置的规则预分区
创建splits.txt文件内容如下:
xxxxxxxxxxaaaabbbbccccdddd
然后执行:
xxxxxxxxxxcreate 'table3','info',SPLITS_FILE => 'splits.txt' 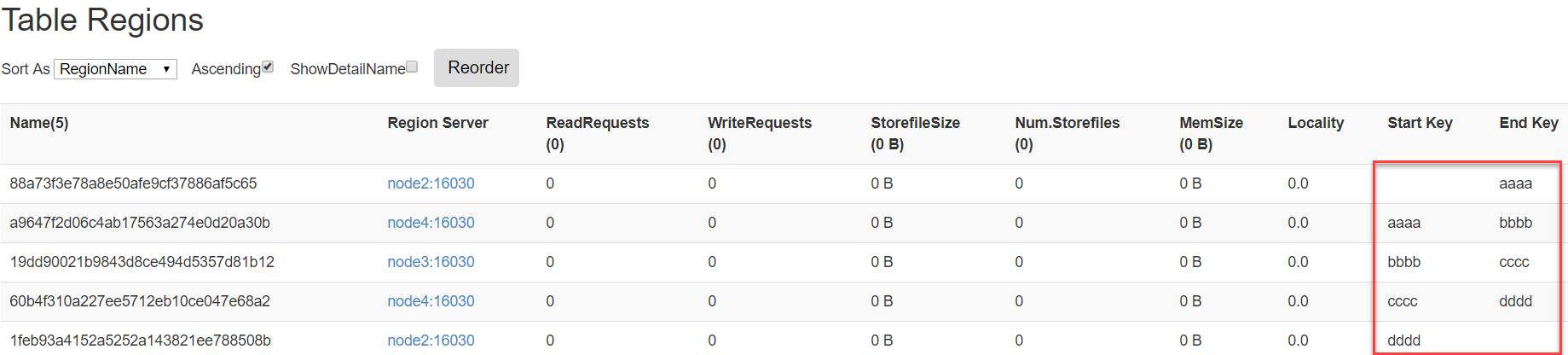
使用JavaAPI创建预分区
xxxxxxxxxx//自定义算法,产生一系列Hash散列值存储在二维数组中byte[][] splitKeys = 某个散列值函数//创建HbaseAdmin实例HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create());//创建HTableDescriptor实例HTableDescriptor tableDesc = new HTableDescriptor(tableName);//通过HTableDescriptor实例和散列值二维数组创建带有预分区的Hbase表hAdmin.createTable(tableDesc, splitKeys);