 目录
目录大数据全系列 教程
1869个小节阅读:464.8k


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

具体步骤:
日志采集接口准备好,Kafka中建立好对应的topic,生产数据准备好
准备flume的配置文件,使用配置文件music_user.properties启动Flume
创建com.itbaizhan.scala.musicproject.streaming.RealTimePVUV类
根据ConfigUtils.LOCAL_RUN构建不同的SparkSession和SparkContext对象
设置日志级别为Error
使用步骤4创建的SparkContext对象和间隔时长为5秒进行构建StreamingContext对象
xxxxxxxxxxval ssc = new StreamingContext(sc,Durations.seconds(5))由于Kafka消费者offset维护到Redis中,所以需要连接Redis,创建RedisClinet类构建JedisPool对象。
xxxxxxxxxxobject RedisClinet { private val redisTimeOut = 30000 val jedisPoolConfig = new JedisPoolConfig //构建连接池对象,即可以保证线程的安全,又有较高的效率 lazy val pool = new JedisPool(jedisPoolConfig, ConfigUtils.REDIS_HOST, ConfigUtils.REDIS_PORT, redisTimeOut)}RedisClinet类中编写三个方法:
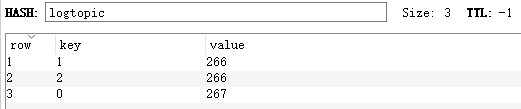
xxxxxxxxxx/**将消费者的offset保存到Reids指定的库中 * @param db 存储消费者偏移量的数据库实例0-15 * @param offsetRanges 偏移量 */def saveOffsetRedis(db:Int,offsetRanges:Array[OffsetRange])={ //获取redis连接 var jedis: Jedis = pool.getResource //选择对应的数据库实例 jedis.select(db) //将偏移量保存 offsetRanges.foreach(offsetRange=>{ //主题、分区号、偏移量 println(s"topic:${offsetRange.topic},partition:${offsetRange.partition.toString},offset:${offsetRange.untilOffset.toString}") jedis.hset(offsetRange.topic,offsetRange.partition.toString,offsetRange.untilOffset.toString) }) println("偏移量保存成功!") //将连接还回去 pool.returnResource(jedis)}/**获取redis中已经存在的主题的偏移量 * @param db 数据库实例 * @param topic 主题名称 * @return 当前主题的各个分区下的偏移量 */def getOffsetFromRedis(db:Int,topic:String):mutable.Map[String,String]={ //获取jedis连接 val jedis: Jedis = pool.getResource //指定redis数据库实例 jedis.select(db) //从指定的数据库实例中读取 val resultMap: util.Map[String, String] = jedis.hgetAll(topic) //释放连接 pool.returnResource(jedis) //特殊情况处理,首次获取时 if(resultMap.size() == 0){ //主题创建时使用的是3个分区,默认每个服务开始的偏移量都是0 resultMap.put("0","0") resultMap.put("1","0") resultMap.put("2","0") } //类型转换 import scala.collection.JavaConverters.mapAsScalaMap val offsetMap: mutable.Map[String, String] = mapAsScalaMap(resultMap) offsetMap}
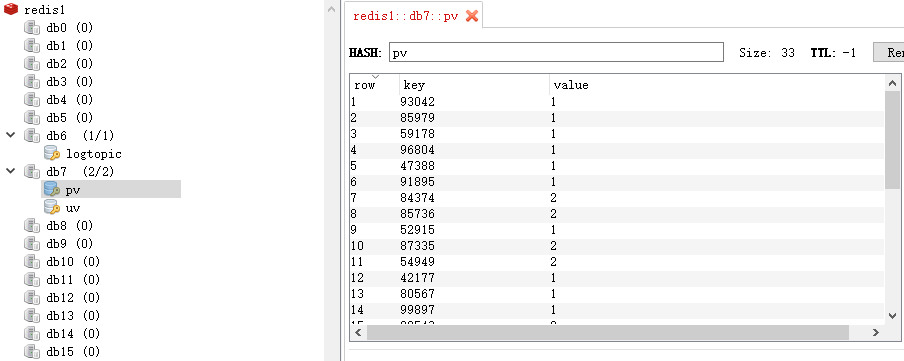
/**将HSet数据值保存到Redis指定的数据库db的指定的key中 * @param key:指定的key,如 pv / uv * @param db:数据库实例 * @param iterator 元素类型(mid,count)的迭代器对象 */def saveHSetToRedis(key:String,db:Int,iterator:Iterator[(String,Int)])={ //获取jedis连接|对象 val jedis: Jedis = pool.getResource //选择数据库实例 jedis.select(db) //pipelined()获取管道,它可以实现一次性发送"多条命令"并一次性返回结果,减少客户端与redis通讯的次数和安全性。 val pipeline: Pipeline = jedis.pipelined() iterator.foreach(tp=>{ pipeline.hset(key,tp._1,tp._2.toString) }) pipeline.sync() println(s"${key} 保存成功") //将连接对象释放 pool.returnResource(jedis)}编写SparkStreaming 读取kafka数据代码 ,pvuv (手动维护消费者offset)
xxxxxxxxxxval currentTopicOffset: mutable.Map[String, String] = RedisClient.getOffSetFromRedis(ConfigUtils.REDIS_OFFSET_DB,ConfigUtils.TOPIC)//初始读取到的topic offset:currentTopicOffset.foreach(tp=>{println(s" 初始读取到的offset: $tp")})//转换成需要的类型val fromOffsets: Predef.Map[TopicPartition, Long] = currentTopicOffset.map { resultSet => new TopicPartition(ConfigUtils.TOPIC, resultSet._1.toInt) -> resultSet._2.toLong}.toMapRealTimePVUV类设置Kafka参数
xxxxxxxxxx//https://spark.apache.org/docs/3.2.1/streaming-kafka-0-10-integration.htmlval kafkaParams = Map[String, Object]( "bootstrap.servers" -> ConfigUtils.KAFKA_BROKERS, "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "MyGroupId11", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean)//默认是true)将获取到的消费者offset 传递给SparkStreaming
xxxxxxxxxxval stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, ConsumerStrategies.Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets))统计PV,并将结果存储在redis中,格式为K:"pv" V:mid,pv数
xxxxxxxxxxstream.map(cr=>{ val jsonObject = JSON.parseObject(cr.value()) val mid = jsonObject.getString("mid") //val uid = jsonObject.getString("uid") (mid,1)}).reduceByKeyAndWindow((v1:Int,v2:Int)=>{v1+v2}, Durations.minutes(1), Durations.seconds(5)) .foreachRDD(rdd=>{ rdd.foreachPartition(iter=>{ //将结果存储在redis中,格式为K:"pv" V:mid,pv数 RedisClient.saveHSetToRedis("pv", ConfigUtils.REDIS_DB,iter) }) })统计UV,并将结果存储在redis中,格式为K:uv V:mid,uv数
xxxxxxxxxxstream.window(Durations.seconds(60),Durations.seconds(5)) .map(cr=>{ val jsonObject = JSON.parseObject(cr.value()) val mid = jsonObject.getString("mid") val uid = jsonObject.getString("uid") (mid,uid)}).transform(rdd=>{ val distinctRDD = rdd.distinct() distinctRDD.map(tp=>{(tp._1,1)})}).reduceByKey((v1:Int,v2:Int)=>{v1+v2}) .foreachRDD(rdd=>{ rdd.foreachPartition(iter=>{ //将结果存储在redis中,格式为K:uv V:mid,uv数 RedisClient.saveHSetToRedis("uv", ConfigUtils.REDIS_DB,iter) }) })将当前批次最后的所有分区offsets 保存到 Redis中
xxxxxxxxxxstream.foreachRDD { (rdd:RDD[ConsumerRecord[String, String]]) => println("所有业务完成") val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //将当前批次最后的所有分区offsets 保存到 Redis中 RedisClient.saveOffsetToRedis( ConfigUtils.REDIS_OFFSET_DB,offsetRanges)}ssc.start()ssc.awaitTermination()ssc.stop()