 目录
目录大数据全系列 教程
1869个小节阅读:466.9k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
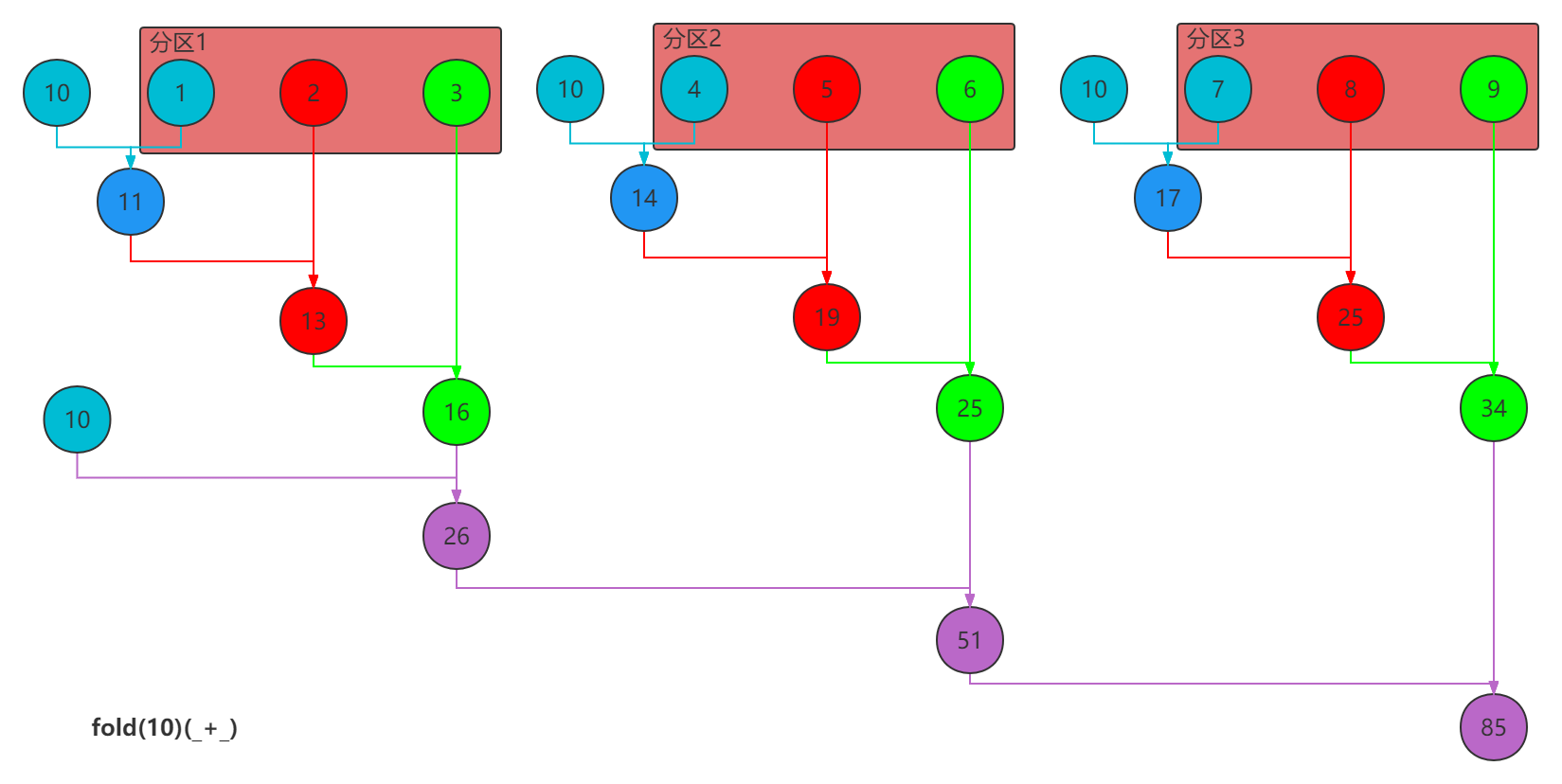
作用:和reduce相似,按照传入的计算逻辑进行聚合,不同的地方是该方法带有初始值,该初始值会被用在:
比如:[[1, 2, 3], [4, 5, 6], [7, 8, 9]]数据分布在3个分区:
分区一:10+1+2+3=16
分区二:10+4+5+6=25
分区三:10+7+8+9=34
分区间聚合:10+16+25+34=85
xxxxxxxxxxpackage com.itbaizhan.rdd.action
//1.导入类import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}
object RddFold { def main(args: Array[String]): Unit = { //2.构建SparkConf对象,并设置本地运行和程序名称 val conf: SparkConf = new SparkConf().setMaster("local[1]"). setAppName("fold") //3.使用conf对象构建SparkContet对象 val sc = new SparkContext(conf) //5.创建RDD对象 //val rdd: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 1) val rdd: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3) //6.执行带有初始值的fold聚合操作 //10表示初始值,_+_表示做聚合加操作 //RDD对象中所有元素的和+(partitionNum+1)*10 val result: Int = rdd.fold(10)(_ + _) //7.注意:初始值的类型要和RDD中数据的类型一致 //rdd.fold(10.5)(_+_)//错误的 println(result) //4.关闭sc对象 sc.stop() }}实时效果反馈
1. fold和reduce相似,按照传入的计算逻辑进行聚合,不同的地方是该方法带有初始值,该初始值会被用在:
A 分区内聚合。
B 分区间聚合。
C 以上两个选项都正确。
答案:
1=>C