 目录
目录大数据全系列 教程
1869个小节阅读:464.8k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

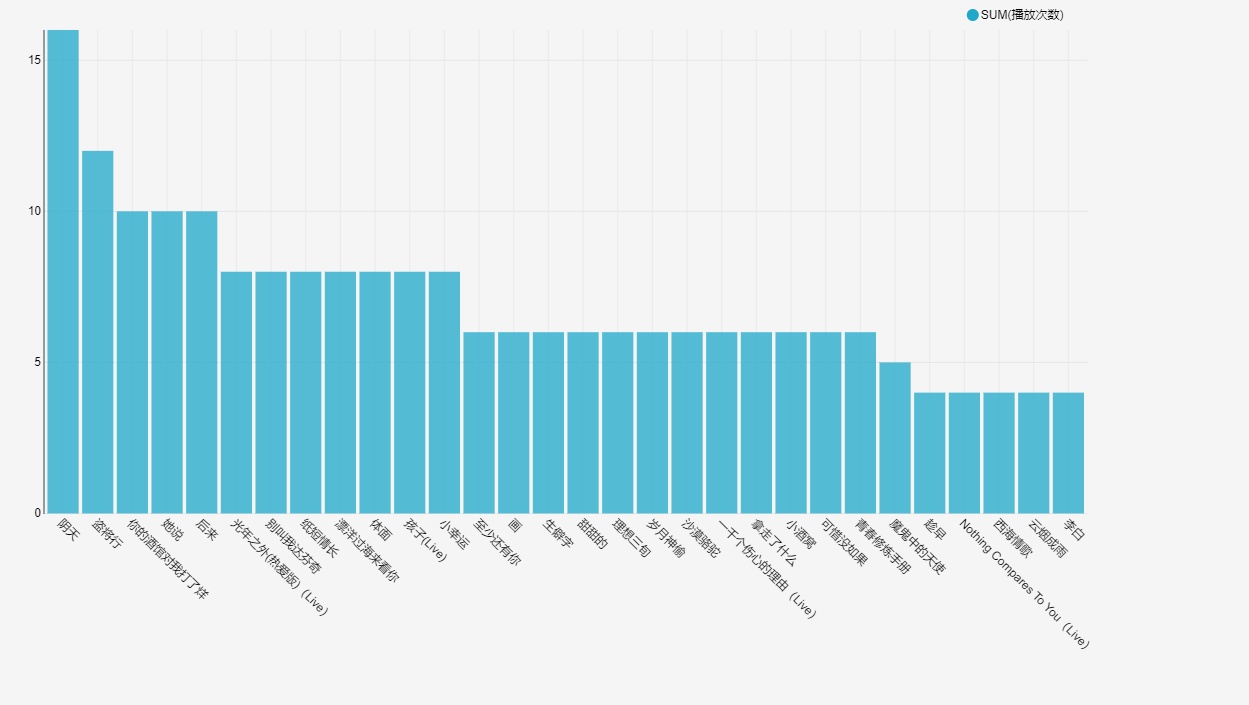
实时从歌曲点播日志中获取用户点播歌曲热榜,每隔10秒,获取最近10分钟歌曲点播热度,并将前30首结果存入MySQL中,Kafka的偏移量手动维护在redis中。
数据来源:client_play_songinfo
{"songid": "10035283", "mid": 52949, "optrate_type": 0, "uid": 49915734, "consume_type": 0, "play_time": 0, "dur_time": 0, "session_id": 89210, "songname": "岁月神偷", "pkg_id": 2, "order_id": "W20191203041257_3_49915734_52949"}
创建com.itbaizhan.scala.musicproject.streaming.RealTimeHotSong类
根据ConfigUtils.LOCAL_RUN构建不同的SparkSession和SparkContext对象
设置日志级别为Error
使用步骤3创建的SparkContext对象和间隔时长为10秒进行构建StreamingContext对象
从Redis 中获取消费者在主题songinfo的偏移量,并转化为需要的类型。
设置Kafka参数
将获取到的消费者offset 传递给SparkStreaming
从流中解析出歌曲名称,转化为(songName,1)
每隔10秒统计过去10分钟内的播放总次数
遍历上步计算后的RDD,将里面的元素转化为样例类HotSongInfo(songName:String,times:Int)
然后通过SparkSQL将上步的结果提取出排名前30的歌曲保存在mysql的songresult.hotsong表中
手动将当前批次最后的所有分区offsets 保存到 Redis中