 目录
目录大数据全系列 教程
1869个小节阅读:467.2k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
RDD的数据是过程数据,RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失,RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。 这个特性可以最大化的利用资源,老旧RDD没用了就从内存中清理,给后续的计算腾出内存空间。
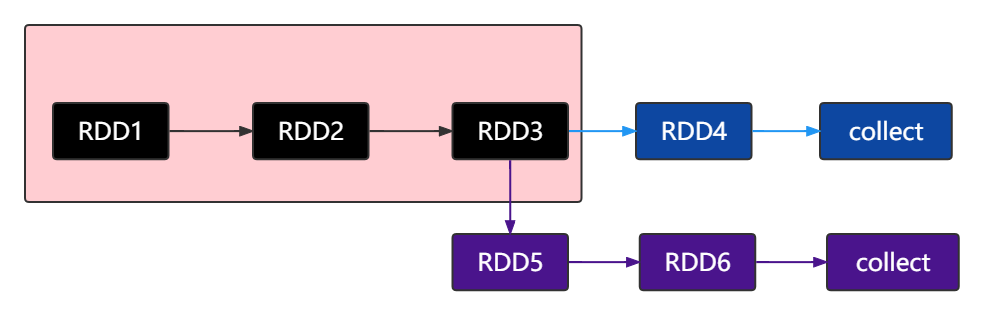
RDD3中的数据在第一次被RDD4使用完之后,就不存在了。当RDD5第二次使用RDD3的数据时,只能通过血缘关系从RDD1->RDD2->RDD3重新执行才能构建出RDD3。所以上图框中的部分执行了两次。
RDD通过cache或者persist方法将前面的计算结果RDD3的数据缓存起来,默认情况下会把数据以缓存在JVM的堆内存或磁盘中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
存储级别如下:
xxxxxxxxxxDISK_ONLY:仅缓存到硬盘 (适用于内存比较紧张的集群)DISK_ONLY_2: 仅缓存到硬盘 2个副本MEMORY_ONLY: 仅缓存到内存MEMORY_ONLY_2: 仅缓存到内存 2个副本DISK_ONLY_3: 仅缓存到硬盘 3个副本MEMORY_AND_DISK: 向缓存到内存,内存不够再放硬盘 (推荐使用)MEMORY_AND_DISK_2: 向缓存到内存,内存不够再放硬盘 2个副本OFF_HEAP: #堆外内存(即系统内存)这对RDD3的缓存通过:
xxxxxxxxxx//开启缓存,使用默认的存储级别MEMORY_AND_DISKrdd3.cache() //开启缓存,使用设置存储级别MEMORY_ONLYrdd3.persist(StorageLevel.MEMORY_ONLY)//以上两者选其一即可
//最终清理缓存rdd3.unpersist()缓存如何保存的?
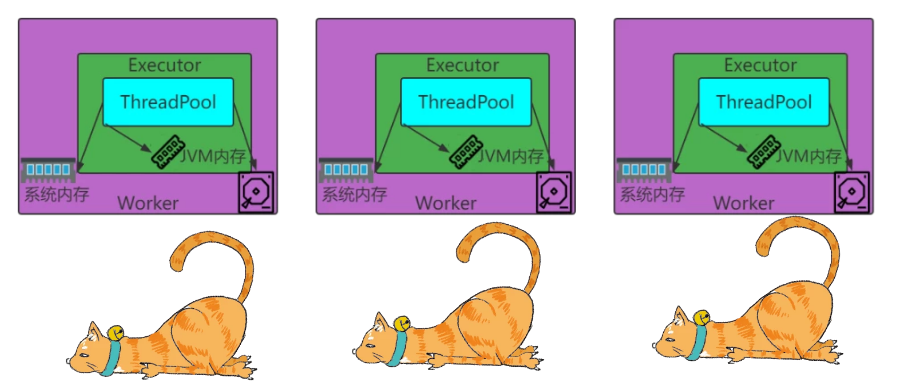
存有可能丢失:
RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
Spark会自动对一些Shuffle操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
实时效果反馈
1. 关于RDD缓存的描述,错误的是:
A RDD通过cache和persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存或磁盘中。
B RDD调用完cache和persist方法后会立即将前面的计算结果缓存。
C MEMORY_ONLY: 仅缓存到内存,这里的内存指定时JVM虚拟机的内存。
D 缓存的数据存在丢失的风险。
答案:
1=>B 并不是这两个方法被调用时立即缓存,而是触发后面的action算子时