 目录
目录大数据全系列 教程
1869个小节阅读:468.1k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
当用户向HRegionServer发起HTable.put(Put)请求时,其会将请求交给对应的HRegion实例来处理。
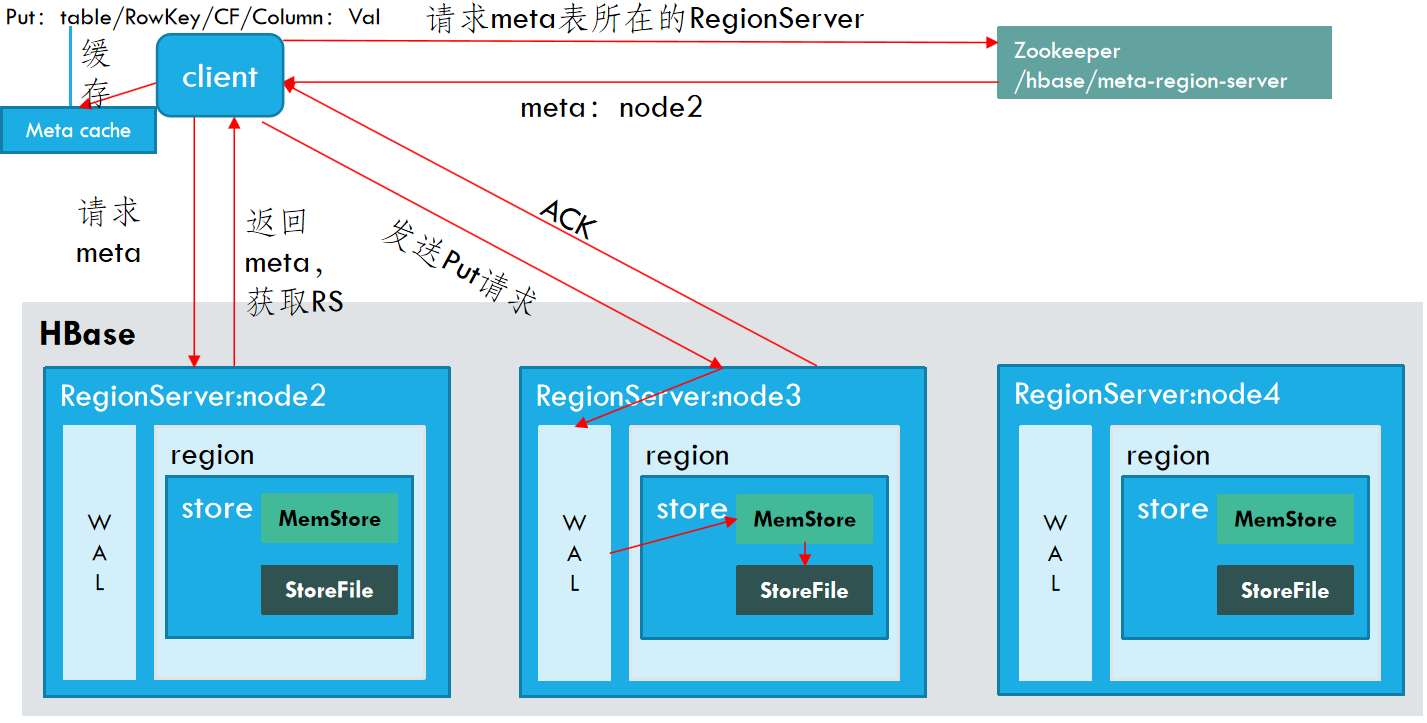
Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
与目标Region Server进行通讯;
将数据顺序写入(追加)到WAL;
将数据写入对应的MemStore,数据会在MemStore进行排序;
向客户端发送ACK;
等达到MemStore的刷写时机后,将数据刷写到HFile。
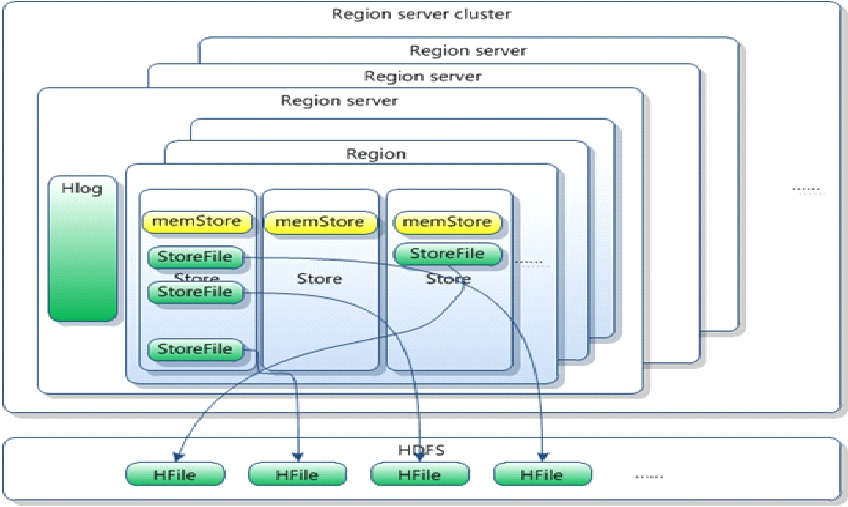
注意:要决定数据是否需要写到由HLog类实现的预写日志中。WAL是标准的Hadoop SequenceFile,并且存储了HLogKey实例。这些键包括序列号和实际数据,所以在服务器崩溃时可以回滚还没有持久化的数据。
一旦数据被写入到WAL中,数据就会被放到MemStore中。同时还会检查MemStore是否已经满了,如果满了,就会被请求刷写到磁盘中去。刷写请求由当前HRegionServer的另外一个线程处理,它会把数据写成HDFS中的一个新HFile。同时也会保存最后写入的序号,系统就知道哪些数据现在被持久化了。
多次数据刷写之后会创建许多数据存储文件,后台线程就会自动将小文件聚合成大文件,这样磁盘查找就会被限制在少数几个数据存储文件中。磁盘上的树结构也可以拆分成独立的小单元,这样更新就可以被分散到多个数据存储文件中。所有的数据存储文件都按键排序,所以没有必要在存储文件中为新的键预留位置。
查询时先查找内存中的存储,然后再查找磁盘上的文件。这样在客户端看来数据存储文件的位置是透明的。
删除是一种特殊的更改,当一条记录被删除标记之后,查找会跳过这些删除过的键。当页被重写时,有删除标记的键会被丢弃。