 目录
目录大数据全系列 教程
1869个小节阅读:467.2k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
1.工作机制
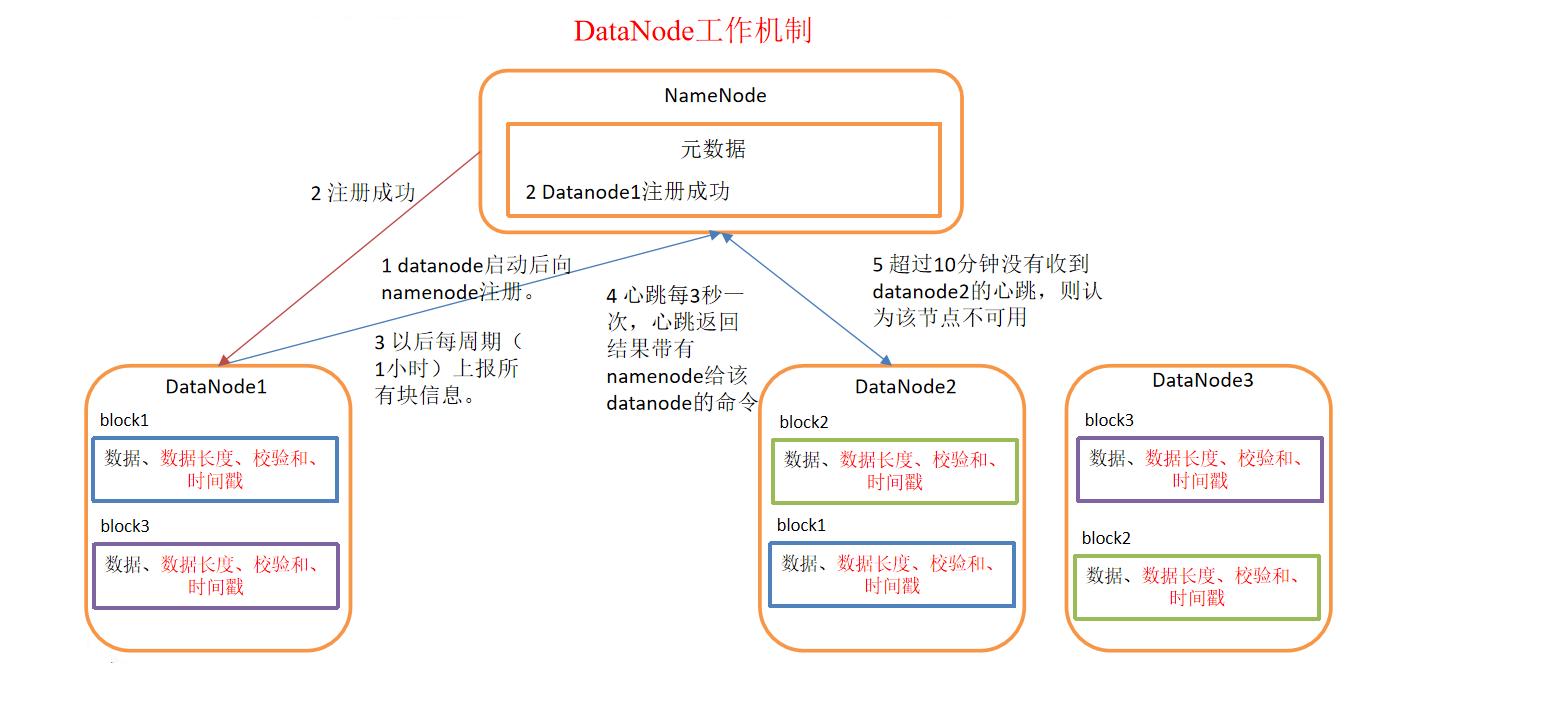
2.存储结构
DataNode不需要显式地格式化;关键文件和目录结构如下:

1、HDFS块数据存储于blk_前缀的文件中,包含了被存储文件原始字节数据的一部分。
2、每个block文件都有一个.meta后缀的元数据文件关联。该文件包含了一个版本和类型信息的头部,后接该block中每个部分的校验和。
3、每个block属于一个block池,每个block池有自己的存储目录,该目录名称就是该池子的ID(跟NameNode的VERSION文件中记录的block池ID一样)。
当一个目录中的block达到64个(通过dfs.datanode.numblocks配置)的时候,DataNode会创建一个新的子目录来存放新的block和它们的元数据。这样即使当系统中有大量的block的时候,目录树也不会太深。同时也保证了在每个目录中文件的数量是可管理的,避免了多数操作系统都会碰到的单个目录中的文件个数限制(几十几百上千个)。
如果dfs.datanode.data.dir指定了位于在不同的硬盘驱动器上的多个不同的目录,则会通过轮询的方式向目录中写block数据。需要注意的是block的副本不会在同一个DataNode上复制,而是在不同的DataNode节点之间复制。
3.存储数据模型(重点)

1、文件线性切割成块(Block)(按字节切割)
xxxxxxxxxx[root@node1 ~]# for i in `seq 100000`; do echo "hello gtjin $i" >> hello.txt; done[root@node1 ~]# cat hello.txthello gtjin1.....hello gtjin100......2、Block分散存储在集群节点中
3、单一文件Block大小一致,文件与文件可以不一致
xxxxxxxxxxhdfs dfs -D dfs.blocksize=1048576 -D dfs.replication=2 -put hello.txt /4、Block可以设置副本数,副本分散在不同节点中
a) 副本数不要超过DataNode节点数量
b) 承担计算
c) 容错
5、文件上传可以设置Block大小和副本数
6、已上传的文件Block副本数可以调整,大小不变
7、只支持一次写入多次读取;对同一个文件,一个时刻只有一个写入者
8、可以append追加数据
4.优势(了解)