 目录
目录大数据全系列 教程
1869个小节阅读:464.7k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
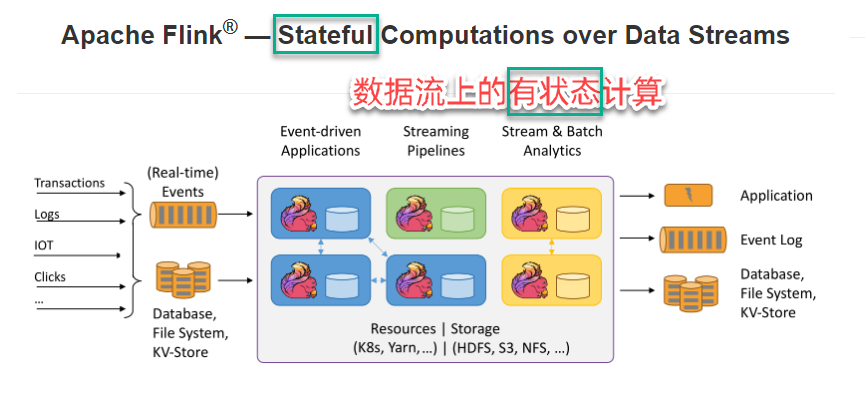
在 Flink 中,算子任务可以分为无状态和有状态两种情况。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。

有状态
task/operator在某时刻的一个中间结果。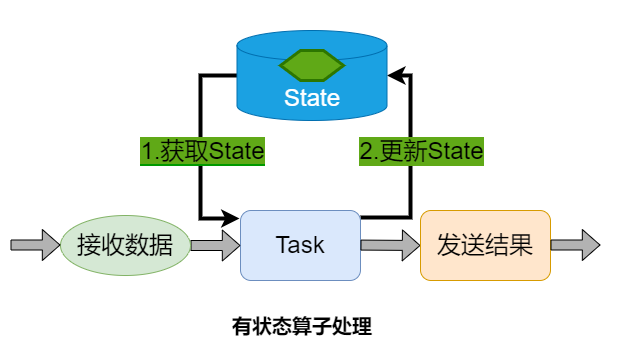
有状态算子处理主要有两个步骤:
1.获取当前状态
2.根据具体的业务逻辑进行计算,使用计算后的结果更新当前状态。
有状态计算案例分析:

为什么Flink知道之前已经处理过一次 'a'和'b'?
原因就是 state发挥作用了,它 存储了之前统计后的结果数据,所以Flink 程序知道'a'和'b'词频。
扩展:Apache Flink作为一个计算框架,提供了有状态的计算,封装了一些底层的实现,比如状态的高效存储、Checkpoint和Savepoint持久化备份机制、计算资源扩缩容等问题。因为Flink接管了这些问题,开发者只需调用Flink API,这样可以更加专注于业务逻辑。
思考:为什么流式计算中需要State状态呢?
代码参考:
xxxxxxxxxxpackage com.itbaizhan.flink.scala.stateobject WordCountState { def main(args: Array[String]): Unit = { //导入隐式转换 import org.apache.flink.streaming.api.scala._ val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1)//设置并行度为1 env.socketTextStream("node3", 8888) .filter(_.trim.length>0)//过滤掉空行 .flatMap(_.split("\\s+"))//按空格拆分 .map((_, 1)) //每个单词计数为1 .keyBy(_._1) .sum(1)//分组统计 .print() //触发执行-execute env.execute("WordCountState") }}