 目录
目录大数据全系列 教程
1869个小节阅读:468.1k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
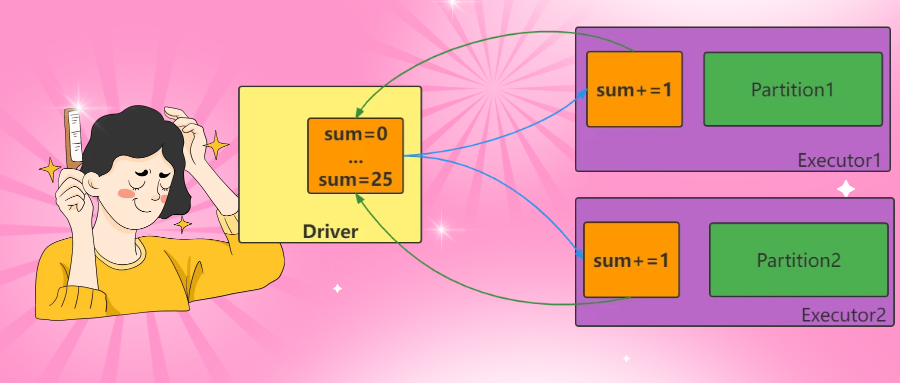
代码演示:
xxxxxxxxxxpackage com.itbaizhan.core
import org.apache.spark.rdd.RDDimport org.apache.spark.util.LongAccumulatorimport org.apache.spark.{SparkConf, SparkContext}
object CoreAccumulator2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("Accumulator2") val sc = new SparkContext(conf) //1.创建一个rdd对象 val rdd: RDD[Int] = sc.parallelize(Range(1, 26, 1).toList, 2) //2.创建一个累加器对象 //sc.longAccumulator(0)//该方式已经过时 val sum: LongAccumulator = sc.longAccumulator("myFirstAcc") //如果担心之前被使用过,怕产生不必要的干扰,可以重置 //sum.reset() //3.自定义一个函数 def mapFunc(data:Int): Int ={ sum.add(1) print(sum.value+",") return data } val result: Array[Int] = rdd.map(mapFunc).collect() println() println(result.mkString(",")) println("driver sum:"+sum.value)//25 sc.stop() }}实时效果反馈
1. 关于Spark累加器的相关描述,正确的是:
A 在Driver程序中定义的普通变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,不改变Driver端变量的值。
B 在Driver程序中定义的累加器变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
C 累加器可用于跨Task任务进行计数统计。
D 以上三个选项都正确。
答案:
1=>D。