 目录
目录大数据全系列 教程
1869个小节阅读:467.8k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
Spark仅做计算,而Hadoop生态圈不仅有计算MapReduce、也有存储HDFS和资源管理调度YARN,HDFS和YARN仍是许多大数据体系的核心架构。Spark依然需要Hadoop的支持。
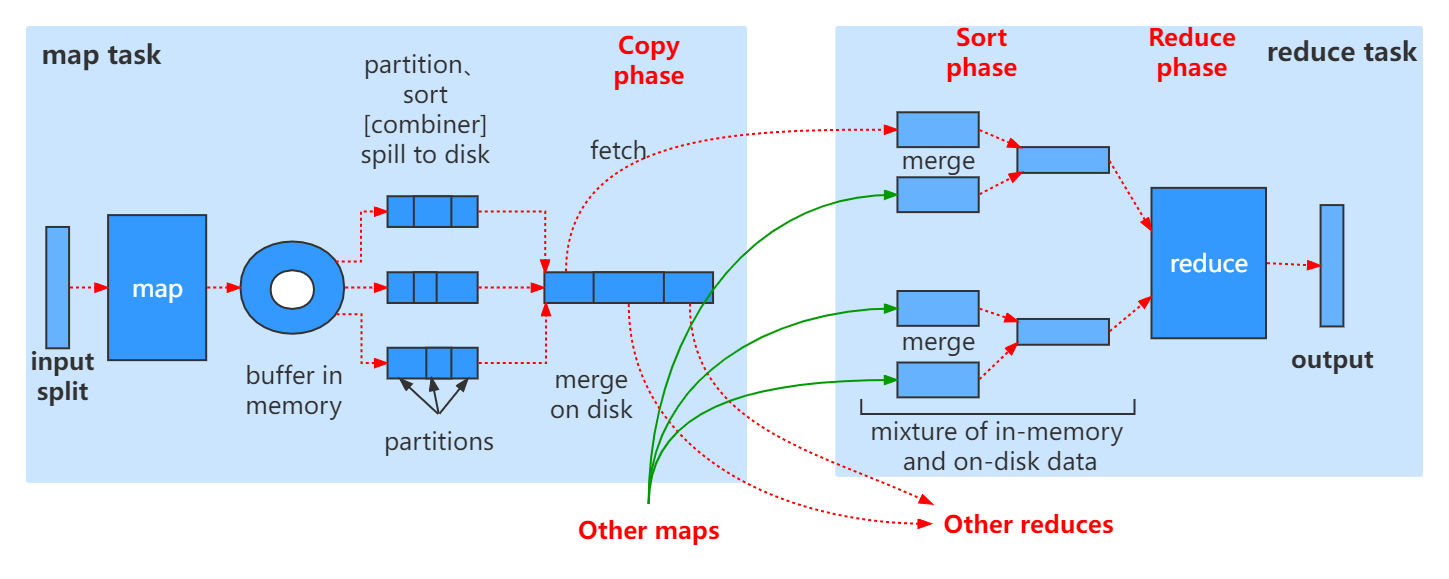
MR在计算过程中中间结果涉及到多次磁盘持久化。
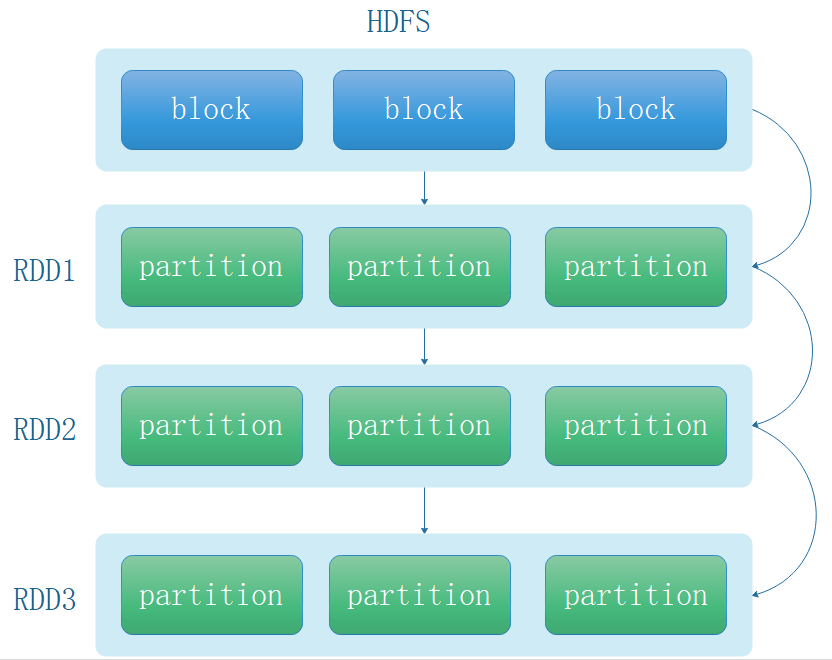
Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
注意:在计算层面,Spark相比较MapReduce有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive。
实时效果反馈
1. 关于Spark和Hadoop的描述,错误的是:
A Spark计算速度明显高于Hadoop,所以Spark可以取代Hadoop。
B Spark仅做计算,而Hadoop生态圈不仅有计算MapReduce、也有存储HDFS和资源管理调度YARN。
C 在计算层面,Spark相比较MapReduce有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive。
D Spark借鉴了MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。
答案:
1=>A 长期共存,无法取代。