 目录
目录大数据全系列 教程
1869个小节阅读:467.8k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
#五、MapReduce源码分析
在WCMapper类中的map方法的首行添加如下代码:
xxxxxxxxxxThread.sleep(99999999);重新打jar包
上传到hadoop集群中,重新运行
xxxxxxxxxxyarn jar wc.jar com.itbaizhan.WCDriver /wordcount/input /wordcount/output3在hadoop集群中的任何节点上执行如下命令:
xxxxxxxxxx[root@node2 ~]# hdfs dfs -ls -R /tmp/hadoop-yarn/drwx------ - root supergroup 0 2021-10-29 03:49 /tmp/hadoop-yarn/staging/root/.staging/job_1635443832663_0002
下载文件夹/tmp/hadoop-yarn/staging/root/.staging/job_1635443832663_0002
xxxxxxxxxx[root@node2 ~]# hdfs dfs -get /tmp/hadoop-yarn/staging/root/.staging/job_1635443832663_0002从该节点的/root目录下下载到windows系统的桌面上,内容列表如下
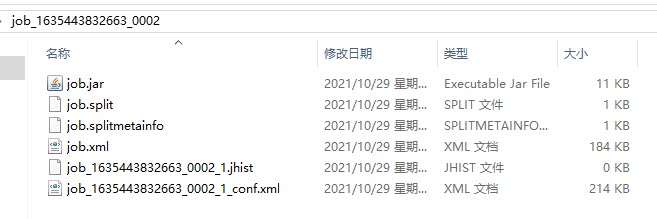
job.jar:作业的jar包
job.xml:当前作业的参数的配置文件
job.split和job.splitmetainfo:当前作业的逻辑切片的相关信息文件
将job.xml拷贝到wordcount项目的根目录,然后进行格式化(目的:方便查看参数),使用Ctrl+Alt+L进行格式化。
配置信息的来源:
默认配置信息:
一部分来源于MRJobConfig接口
一部分来至于*-default.xml文件
自定义的信息:
一部分来至于xxx-site.xml文件
一部分来至于我们通过程序设置的参数