 目录
目录大数据全系列 教程
1869个小节阅读:466k


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
全局查找DefaultPartitioner,先关闭IDEA中打开的所有类,根据自己IDEA的提示选择全局搜索对应的快捷键:按两下Shift键

输入DefaultPartitioner

点击进入DefaultPartitioner.class,如下图所示
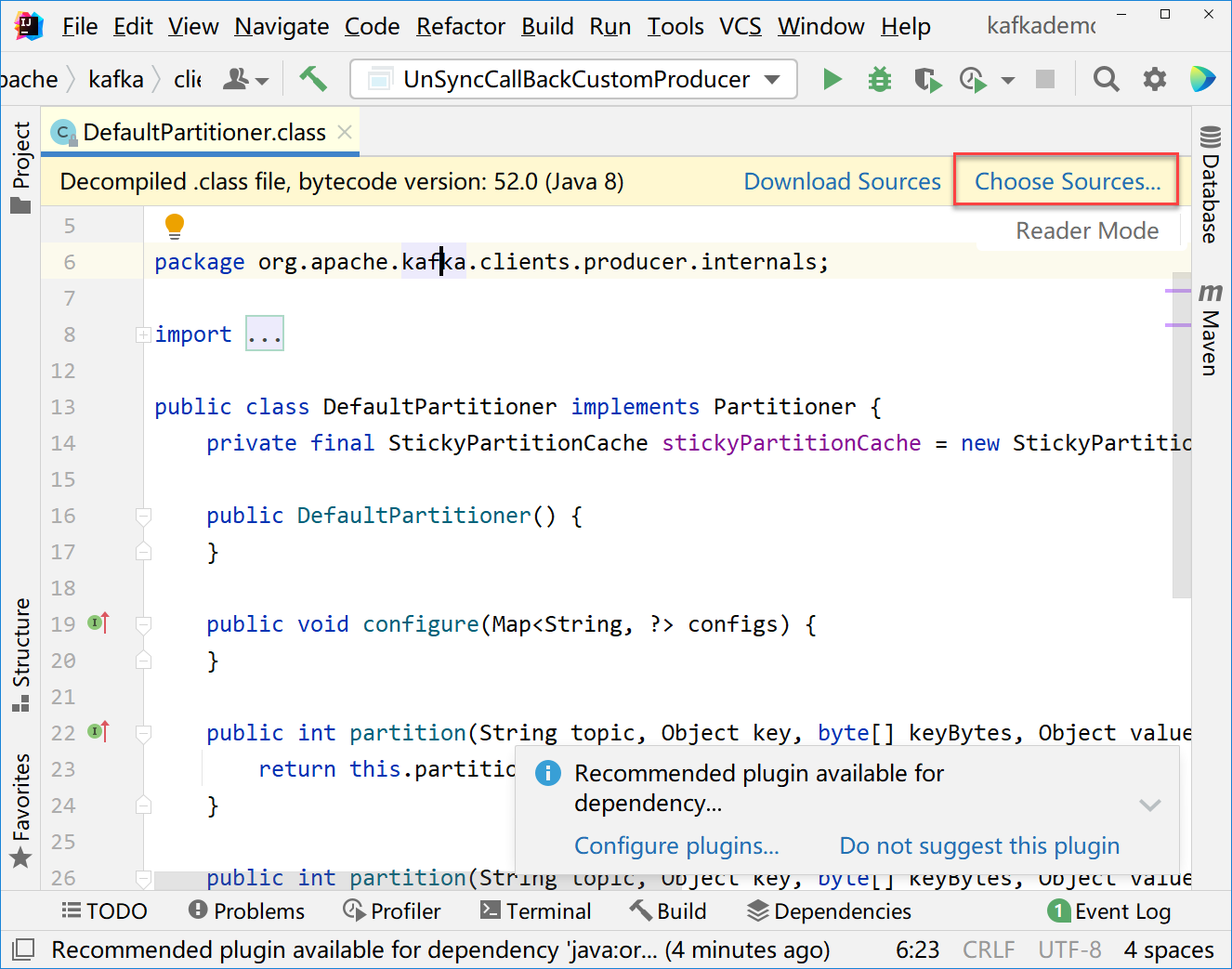
这样的源码不便于阅读。
为了方便阅读源码,需要关联我们下载的kafka-3.0.1-src.tgz。
将kafka-3.0.1-src.tgz解压到D:\devsoft\src
点击 Choose Sources
选择kafka源码文件夹
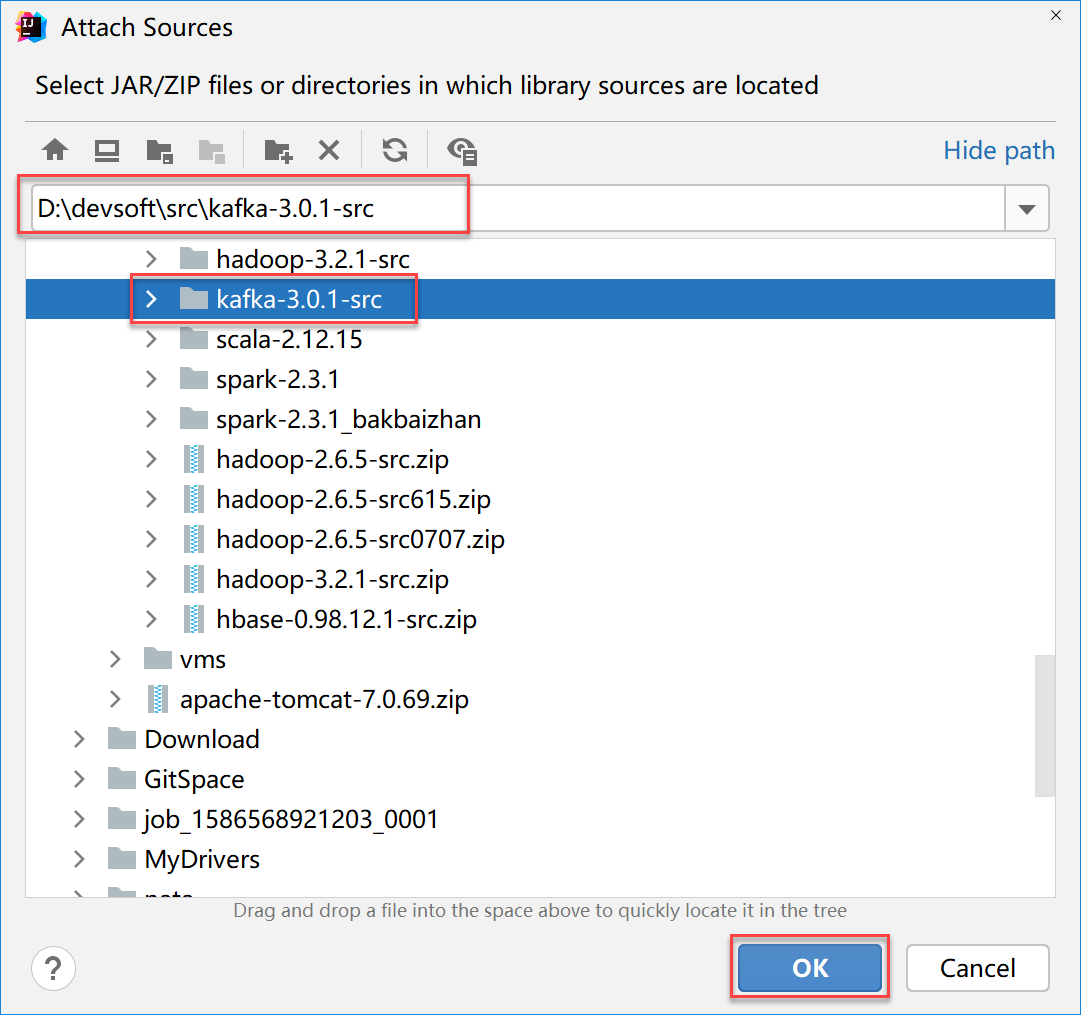
点击OK
然后进入到源码阅读
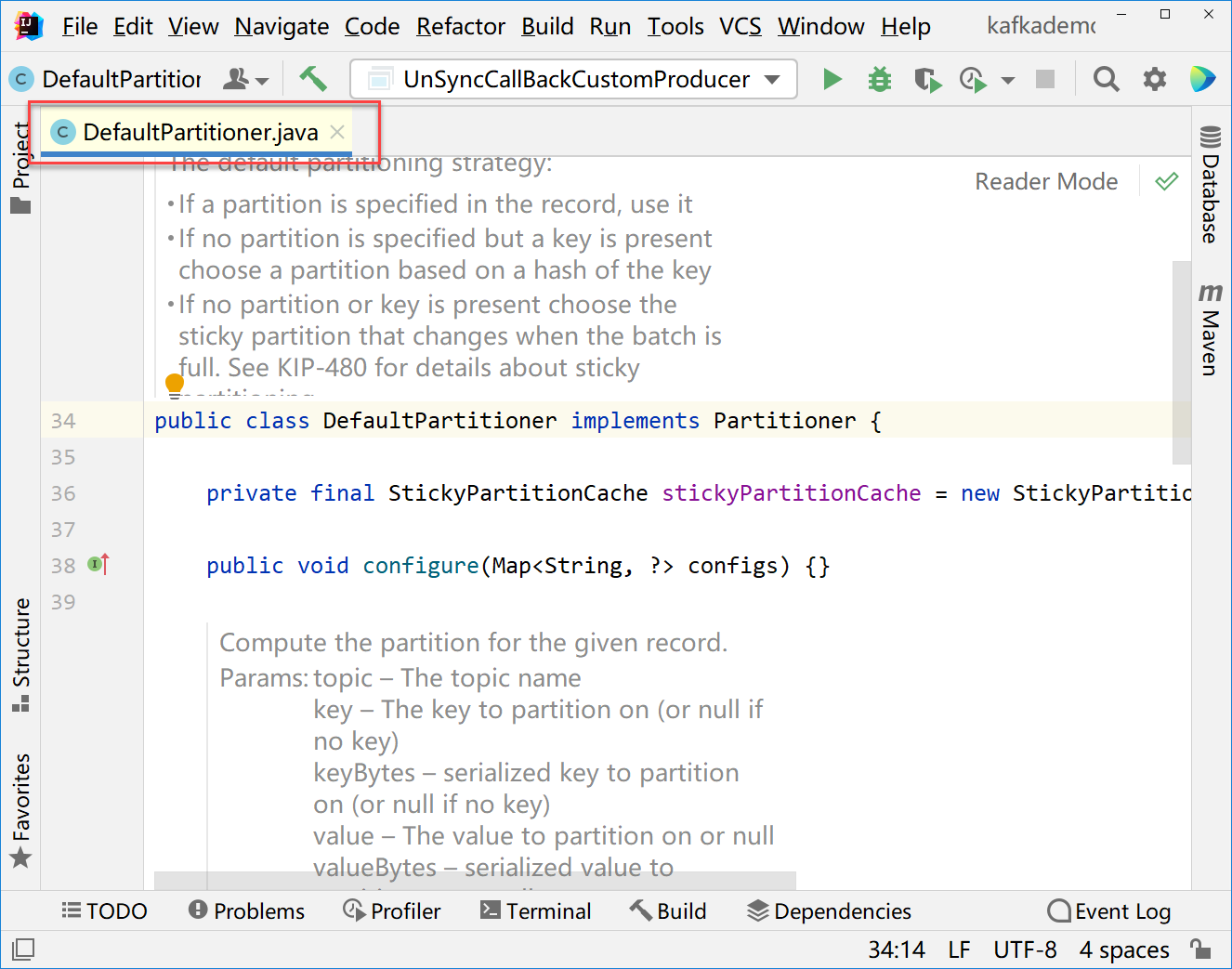
默认分区类的描述信息:
xxxxxxxxxx/** * The default partitioning strategy:默认的分区策略 * <ul> * <li>If a partition is specified in the record, use it 如果在记录中指定了一个分区,请使用它。 * <li>If no partition is specified but a key is present choose a partition based on a hash of the key 如果没有指定任何分区,但存在一个键,则基于键的hash值%分区数的结果选择一个分区 * <li>If no partition or key is present choose the sticky partition that changes when the batch is full. 如果没有分区或键,请选择批处理满时更改的粘性分区。 * * See KIP-480 for details about sticky partitioning. */public class DefaultPartitioner implements Partitioner {xxxxxxxxxx/** * Compute the partition for the given record. * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes serialized key to partition on (or null if no key) * @param value The value to partition on or null * @param valueBytes serialized value to partition on or null * @param cluster The current cluster metadata */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size()); }/** * Compute the partition for the given record. * 计算给定记录的分区 * @param topic The topic name * @param numPartitions The number of partitions of the given {@code topic} * @param key The key to partition on (or null if no key) * @param keyBytes serialized key to partition on (or null if no key) * @param value The value to partition on or null * @param valueBytes serialized value to partition on or null * @param cluster The current cluster metadata */public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) { if (keyBytes == null) { return stickyPartitionCache.partition(topic, cluster); } // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}//......}xxxxxxxxxxpublic ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) { ......}public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) { this(topic, partition, timestamp, key, value, null);}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) { this(topic, partition, null, key, value, headers);}public ProducerRecord(String topic, Integer partition, K key, V value) { this(topic, partition, null, key, value, null);}xxxxxxxxxxpublic ProducerRecord(String topic, K key, V value) { this(topic, null, null, key, value, null);}xxxxxxxxxxpublic ProducerRecord(String topic, V value) {this(topic, null, null, null, value, null);}
实时效果反馈
1. 关于Kafka分区策略的描述,正确的是:
A 指明partition的情况下,直接将指定的值作为分区值。例如partition=1,对应数据就如分区1。
B 没有具体的partition值而有key的情况下,消息要被发送到的目标分区号partition=Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions。
C 既没有partition值也没有key的情况下,Kafka采用黏性分区器,会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或linger.ms设置的时间到了,再随机一个分区进行使用(通常和上一次的分区不同)。
D 以上三个选项都正确。
答案:
1=>D