 目录
目录大数据全系列 教程
1869个小节阅读:464.8k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
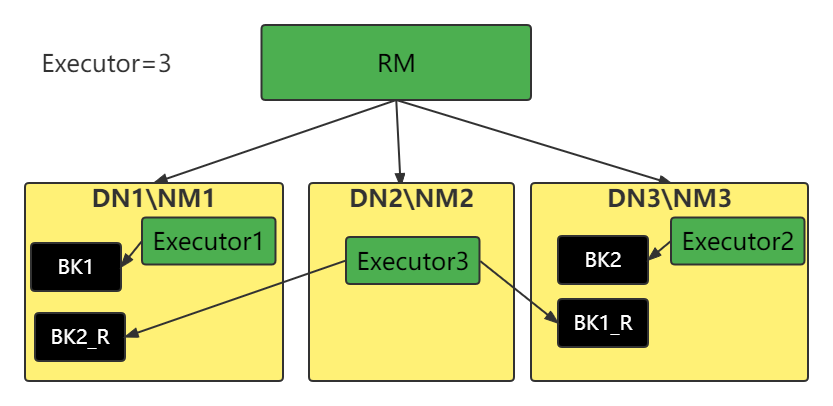
特性5:RDD的分区规划尽量靠近数据所在的服务器
在初始RDD(读取数据的时候)规划的时候,分区会尽量规划到存储数据所在的服务器上。因为这样可以走本地读取,避免网络读取 。
本地读取∶Executor所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读的数据,所以可以直接读取机器硬盘即可无需走网络传输
网络读取∶读取数据 需要经过网络的传输才能读取到,效率远远低于本地读取。
注意:Spark会在确保并行计算能力的前提下,尽量确保本地读取 这里是尽量确保 而不是100%确保。所以这个特性也是∶可能的
实时效果反馈
1. 关于特性5:RDD的分区规划尽量靠近数据所在的服务器错误是:
A 在初始RDD(读取数据的时候)规划的时候,分区会尽量规划到存储数据所在的服务器上。
B 本地读取指的是Executor所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读的数据,所以可以直接读取机器硬盘即可无需走网络传输。
C 所有的场景均可以实现RDD的本地读取。
D Spark会在确保并行计算能力的前提下,尽量确保本地读取 这里是尽量确保 而不是100%确保。
答案:
1=>C 不是所有场景都可以实现本地读取的。