 目录
目录大数据全系列 教程
1869个小节阅读:464.9k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

维度建模主要源自数据集市,主要面向分析场景。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。它与实体-关系(ER)建模有很大的区别,实体-关系建模是面向应用,遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反范式化的设计技术。
Ralph Kimball(拉尔夫·金博尔)推崇数据集市的集合为数据仓库,同时也提出了对数据集市的维度建模,将数据仓库中的表划分为事实表、维度表两种类型。
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。例如,一个按照地区、产品、月份划分的销售量和销售额的事实表如下:
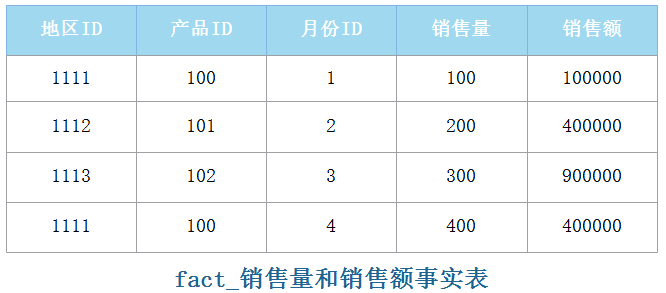
在以上事实表的示例中,“地区ID”、“产品ID”、“月份ID”为键值列,“销售量”、“销售额”为度量列,所谓度量列就是列的数据可度量,度量列一般为可统计的数值列。事实表中每个列通常要么是键值列,要么是度量列。
事实表中一般会使用一个代号或者整数来代表维度成员,而不使用描述性的名称,例如:ID代号。上表中的“地区ID”、“产品ID”、“月份ID”就是维度列,就是观察数据的角度。使用代号或整数来代表维度成员的原因是事实表往往包含很多数据行,使用代号或整数这种键值方式可以有效减少事实表的大小。
在事实表中使用代号或者整数键值时,维度成员的名称需要放在另一种表中,也就是维度表。通常事实表中的每个维度都对应一个维度表。
在数据仓库中,事实表的前缀为“fact”
维度表包含了维度的每个成员的特定名称。维度成员的名称称为“属性”(Attribute),假设“产品ID”维度表中有3种产品,例如:
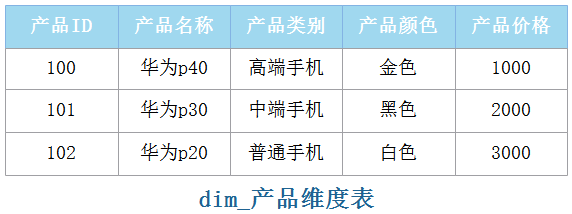
如上图,“产品名称”是产品维度表中的一个属性,维度表中可以包含很多属性列。
产品维度表中的“产品ID”与事实表中的“产品ID”相匹配,称为“键属性”,在当前产品维度表中一个“产品ID”只有一个“产品名称”,显示时使用“产品名称”来代替,所以“产品名称”也被认为是“键属性”的一部分。
在数据仓库中,维度表中的键属性必须为维度的每个成员包含一个对应的唯一值,用关系型数据库术语描述就是,键属性是主键列,也就是说维度表中一般为单一主键。
每个维度表中的键值属性都与事实表中对应的维度相匹配,在维度表中“产品ID”类似关系型数据库中的主键,在事实表中“产品ID”类似关系型数据库中的外键,维度表和事实表就是按照键值属性“产品ID”进行关联的。在维度表中出现一次的每个键值都会在事实表中出现多次。例如上图中,产品ID 中 1111在事实表中对应多行。
在数据仓库中,维度表的前缀为"dim"
总结
在数据仓库中事实表就是我们需要关注的内容,维度表就是我们从哪些角度观察这些内容。例如,某地区商品的销量,是从地区这个角度观察商品销量的。事实表就是销量表,维度表就是地区表。
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。
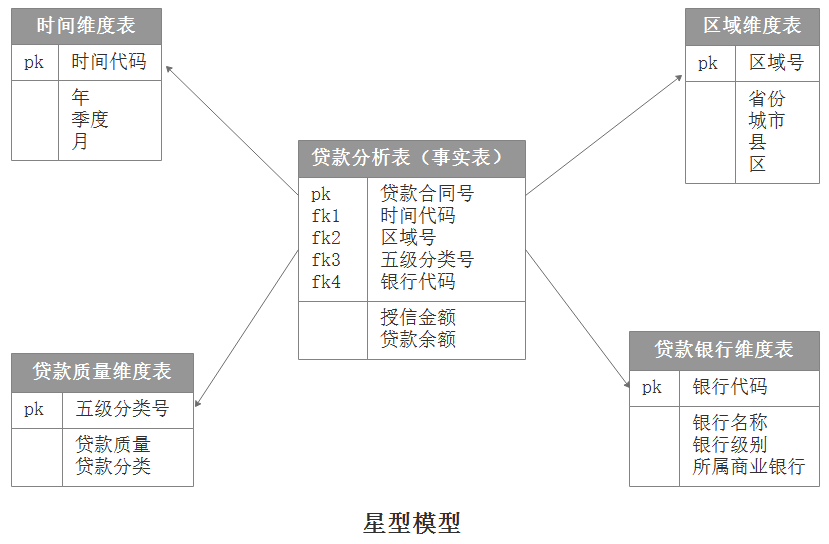
星型模型:
当所有的维度表都由连接键连接到事实表时,结构图如星星一样,这种分析模型就是星型模型。如下图,星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在下图中,时间维中存在A年1季度1月、A年1季度2月两条记录,那么A年1季度被存储了2次,存在冗余。
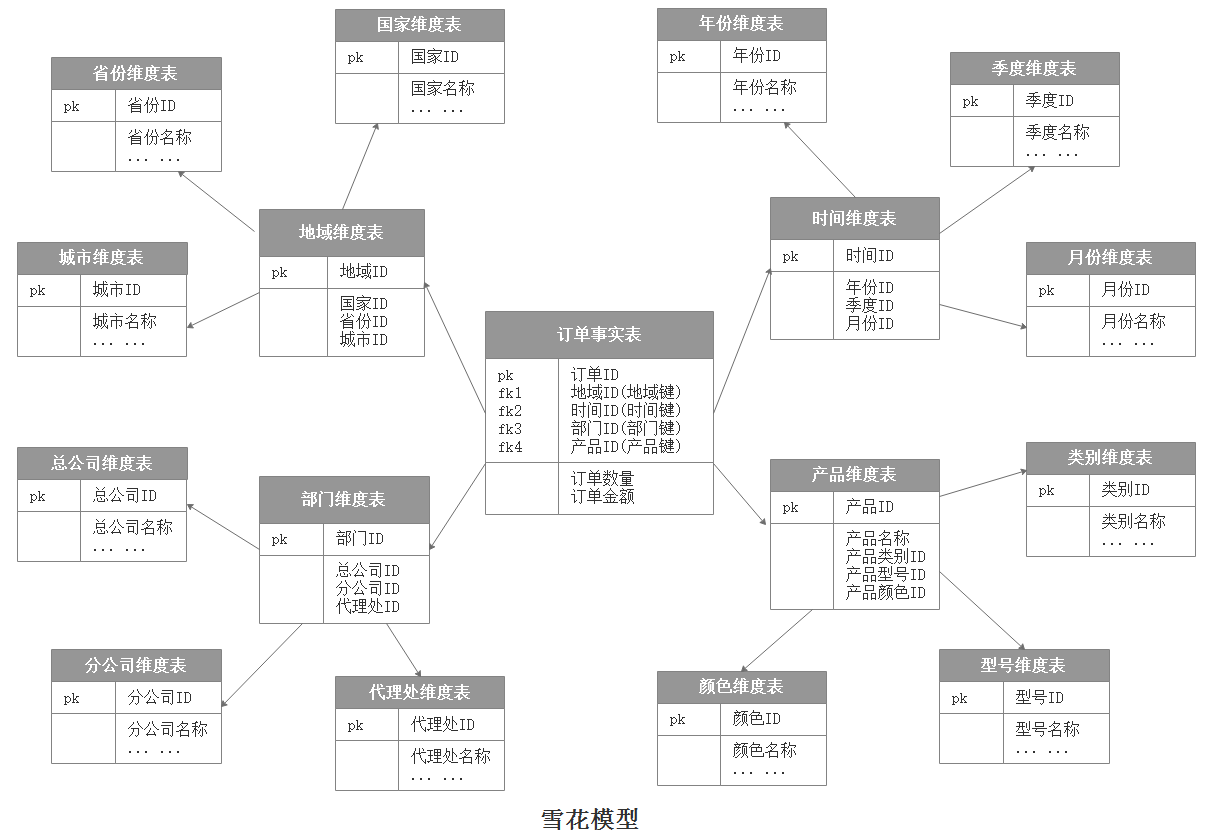
雪花模型:
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其结构图就像雪花连接在一起,这种分析模型就是雪花模型。如下图,雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。如下图中,将地域维表又分解为国家,省份,城市等维表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,雪花型结构去除了数据冗余。
星型模型与雪花模型对比:
星型模型和雪花模型主要区别就是对维度表的拆分,对于雪花模型,维度表的设计更加规范,一般符合三范式设计;而星型模型,一般采用降维的操作,维度表设计不符合三范式设计,反规范化,利用冗余牺牲空间来避免模型过于复杂,提高易用性和分析效率。
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,数仓构建实际运用中星型模型使用更多,也更有效率。
此外,在数据仓库中星座模型也使用比较多,当多个事实表共用多张维度表时,就构成了星型模型。
实时效果反馈
1. 关于维度建模的描述,错误的是:
A 维度建模主要源自数据集市,主要面向分析场景。
B 维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
C Ralph Kimball(拉尔夫·金博尔)推崇数据集市的集合为数据仓库,同时也提出了对数据集市的维度建模,将数据仓库中的表划分为事实表、维度表两种类型。
D 在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和网络型模型。
答案:
1=>D 可将常见的模型分为星型模型和雪花型模型。