目录
目录大数据全系列 教程
1869个小节阅读:467.2k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
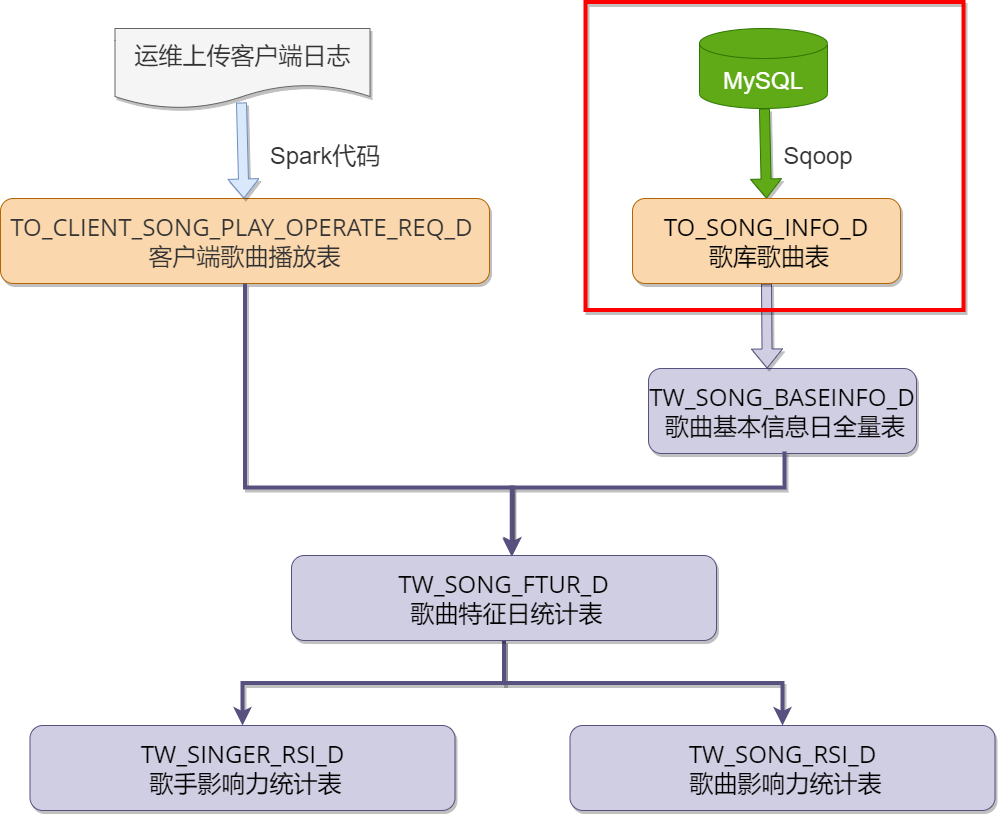
将MySQL中的“songdb”库中的“song”表通过Sqoop抽取到对应的ODS层表TO_SONG_INFO_D中,这里需要使用Sqoop工具,每天定时全量覆盖更新到Hive中。
操作步骤:
MySQL中创建数据库实例songdb,并导入数据
使用Navicat/SQLyog工具连接mysql,创建songdb库
在“songdb”库中导入“songdb.sql”文件,将“song”数导入到MySQL的songdb.song表中。
node3(Sqoop节点)上编写Sqoop导入脚本ods_mysqltohive_to_song_info_d.sh
xxxxxxxxxx[root@node3 ~]# vim ods_mysqltohive_to_song_info_d.sh内容如下:
xxxxxxxxxximport--connectjdbc:mysql://node1:3306/songdb?dontTrackOpenResources=true&defaultFetchSize=10000&useCursorFetch=true&useUnicode=yes&characterEncoding=utf8--usernameroot--password123456--tablesong--target-dir/user/hive_remote/warehouse/data/song/TO_SONG_INFO_D/--delete-target-dir--num-mappers1--fields-terminated-by\t参数说明:
dontTrackOpenResources=true:你关闭所有的statement和resultset,但是如果你没有关闭connection的话,connection就会引用到statement和resultset上,从而导致GC不能释放这些资源(statement和resultset),当设置参数dontTrackOpenResources=true时,在statement关闭后,resultset也会被关闭,达到节省内存目的。
defaultFetchSize:设置每次拉取数据量。
useCursorFetch=true :设置连接属性useCursorFetch=true (5.0版驱动开始支持),表示采用服务器端游标,每次从服务器取fetch_size条数据。
useUnicode=yes&characterEncoding=utf8 : 设置编码格式UTF8
--username : 数据库用户名
--password : 数据库密码
--table : import出的数据库表
--target-dir : 指定数据导入到HDFS中的路径。
--delete-target-dir :如果数据输出目录已存在则先删除
--num-mappers :当数据导入HDFS中时生成的MR任务使用几个map任务。
--hive-import :将数据从关系数据库中导入到 hive 表中,自动将数据导入到hive中,生成对应--hive-table 指定的表,表中的字段是直接从MySql中映射过来的字段。
--hive-database : 数据导入Hive中使用的Hive 库。
--hive-overwrite :覆盖掉在 Hive 表中已经存在的数据,与append只能使用一个。
--fields-terminated-by : 指定字段列分隔符,默认分隔符是'\001',建议指定分隔符。
--hive-table : 导入的Hive表。
执行命令:
xxxxxxxxxxsqoop --options-file ods_mysqltohive_to_song_info_d.sh执行成功提示:
09-02 14:56:37,887 INFO mapreduce.ImportJobBase: Transferred 40.7476 MB in 45.6428 seconds (914.1752 KB/sec) 09-02 14:56:37,896 INFO mapreduce.ImportJobBase: Retrieved 177315 records. #数据库songdb的表song中的数据行数为177315,表示全部导入
HDFS文件系统查看