 目录
目录大数据全系列 教程
1869个小节阅读:464.7k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
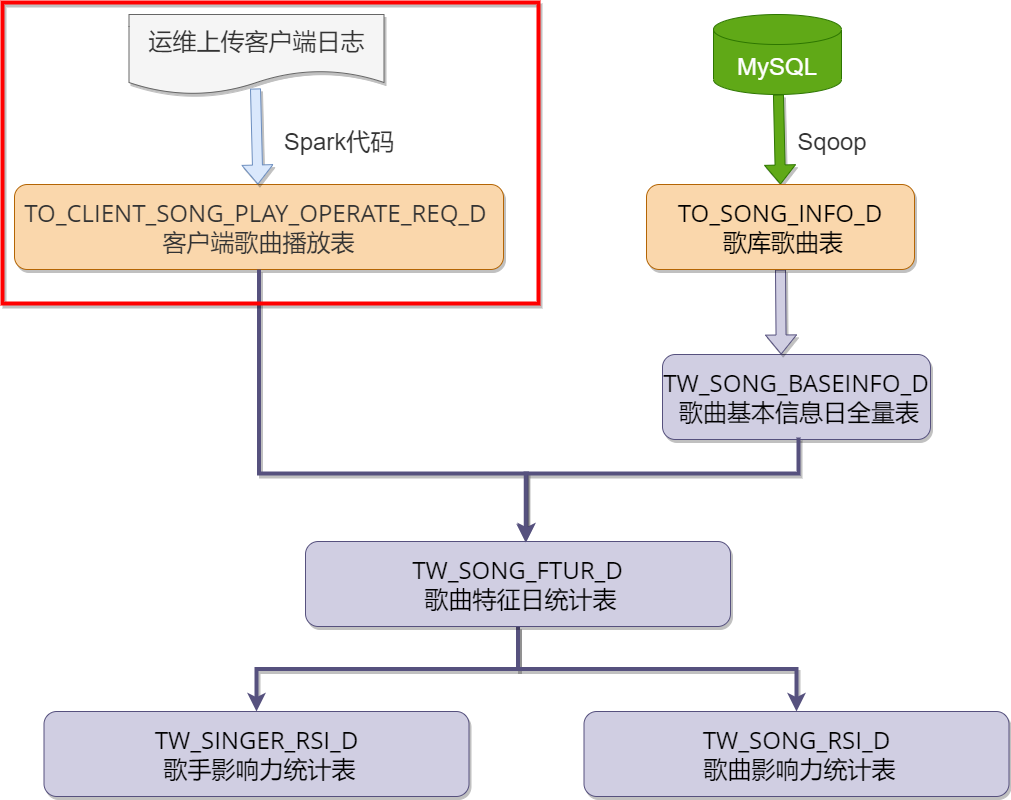
准备客户端日志,上传至HDFS中:
在HDFS文件系统创建/logdata目录
xxxxxxxxxx[root@node1 ~]# hdfs dfs -mkdir /logdata将客户端日志“currentday_clientlog.tar.gz”上传至HDFS目录hdfs://mycluster/logdata下,如果HDFS没有此目录需要先创建这个目录。这里模拟运维人员每天凌晨将数据上传至HDFS中。
清洗客户端日志数据,保存到数仓ODS层思路分解
判断程序传入的参数,未传入参数直接结束程序,并给予提示信息;符合要求将参数赋值
xxxxxxxxxxval logDate = args(0) // 日期格式 : 年月日 20301010根据ConfigUtils.LOCAL_RUN值的不同使用不同的方式构建SparkSession对象,然后构建SparkContext对象sc,调用clientLogInfos : RDD[String]=sc.textFile(path)方法读取演示文件,本地运行和集群运行path路径不同。
首先对clientLogInfos使用map算子将它的元素分解为数组arr,然后数组元素为6(arr.length==6)的日志记录,最后将RDD元素转化为二元组(arr(2),arr(3))后赋值给tableNameAndInfos:RDD[(String,String)]
日志格式如下,每行日志信息被&拆分为了6部分。
1916900543&99702&MINIK_CLIENT_SONG_PLAY_OPERATE_REQ&{"songid": "LX_M012893", "mid": 99702, "optrate_type": 1, "uid": 49915635, "consume_type": 0, "play_time": 201, "dur_time": 272, "session_id": 14089, "songname": "那女孩对我说", "pkg_id": 4, "order_id": "InsertCoin_43347"}&3.0.1.15&2.4.4.30
tableNameAndInfos.map(tp=>{...})将key为MINIK_CLIENT_SONG_PLAY_OPERATE_REQ的value从json中解析出来后形成如下格式:(key,songid+"\t"+mid+"\t"+optrateType+"\t"+uid+"\t"+consumeType+"\t"+durTime+"\t"+sessionId+"\t"+songName+"\t"+pkgId+"\t"+orderId)
key为其它值的保持原内容不变,并将tableNameAndInfos中的数据保存在HDFS文件系统的hdfs://mycluster/logdata/all_client_tables/${logDate}下,使用key作为文件名称。
baizhan_music'${hdfsclientlogpath}/all_client_tables/${logDate}/MINIK_CLIENT_SONG_PLAY_OPERATE_REQ'load到表TO_CLIENT_SONG_PLAY_OPERATE_REQ_D中(注意分区使用${logDate})