 目录
目录大数据全系列 教程
1869个小节阅读:464.7k


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
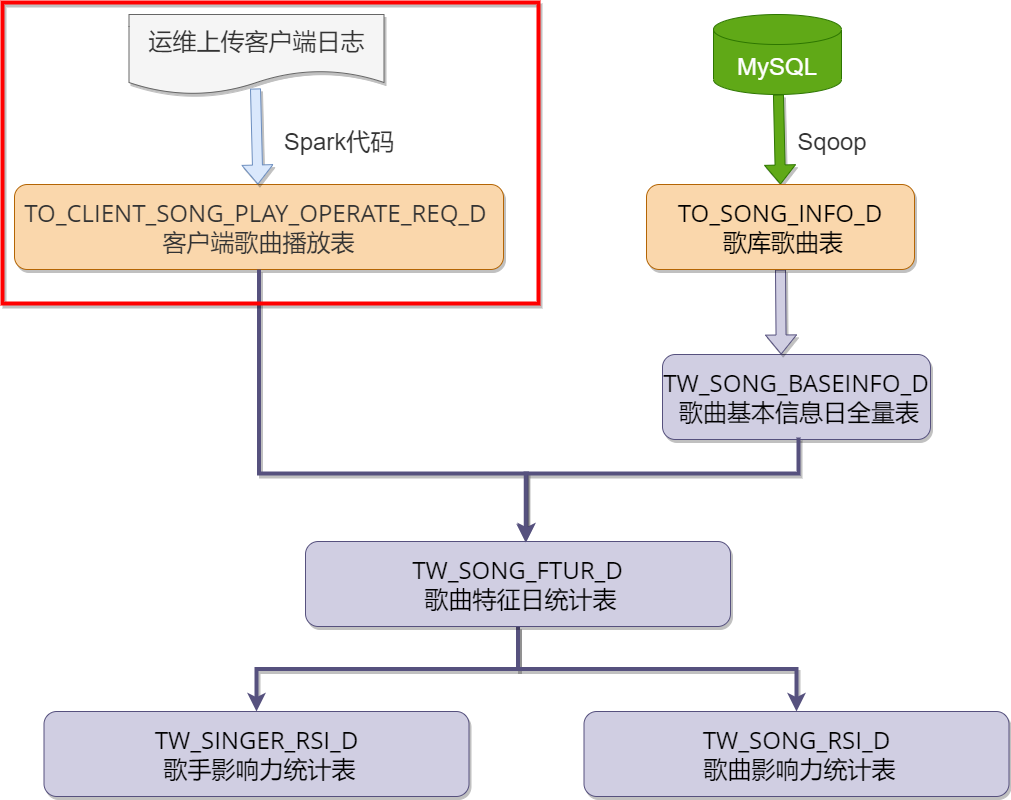
创建类com.itbaizhan.scala.musicproject.ods.ProduceClientLog.scala
判断程序传入的参数,未传入参数直接结束程序,并给予提示信息;符合要求将参数赋值
xxxxxxxxxxpackage com.itbaizhan.scala.musicproject.odsimport com.itbaizhan.scala.musicproject.common.ConfigUtilsimport org.apache.spark.SparkContextimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.SparkSessionobject ProduceClientLog { //定义常量hiveURIS private val hiveMetaStoreUris = ConfigUtils.HIVE_METASTORE_URIS //hive的命名空间 private val hiveDataBase = ConfigUtils.HIVE_DATABASE private var sparkSession:SparkSession = _ private var sc:SparkContext = _ //定义RDD[String]对象,用于接收读取日志文件后的 private var clientLogInfos:RDD[String] = _ def main(args: Array[String]): Unit = { //判断程序传入的参数,未传入参数直接结束程序,并给予提示信息; if(args.length<1){ println("需要指定数据日期,格式如20301010") System.exit(1) } //符合要求将参数赋值 val logDate = args(0) //后续代码在此处编写 }}根据ConfigUtils.LOCAL_RUN值的不同使用不同的方式构建SparkSession对象,然后构建SparkContext对象sc,调用clientLogInfos : RDD[String]=sc.textFile(path)方法读取演示文件,本地运行和集群运行path路径不同。
xxxxxxxxxx//判断是否本地运行if(ConfigUtils.LOCAL_RUN){//表示本地运行1 //构造SparkSession对象 sparkSession = SparkSession.builder() .master("local") .appName("ProduceClientLog") .config("hive.metastore.uris",hiveMetaStoreUris) .enableHiveSupport().getOrCreate() //获取SparkSession对象中的SparkContext对象 sc = sparkSession.sparkContext //设置日志级别 sc.setLogLevel("Error") //读取日志文件 本地项目下的日志文件 clientLogInfos = sc.textFile("file:///D:/code/itbaizhan/baizhan_music/MusicProject/data/currentday_clientlog.tar.gz")}else{//表示非本地运行 sparkSession = SparkSession.builder() .appName("ProduceClientLog") .enableHiveSupport() .getOrCreate() sc = sparkSession.sparkContext sc.setLogLevel("Error") clientLogInfos = sc.textFile(s"${ConfigUtils.HDFS_CLIENT_LOG_PATH}/currentday_clientlog.tar.gz")}首先对clientLogInfos使用map算子将它的元素分解为数组arr,然后数组元素为6(arr.length==6)的日志记录,最后将RDD元素转化为二元组(arr(2),arr(3))后赋值给tableNameAndInfos:RDD[(String,String)]
日志格式如下,每行日志信息被&拆分为了6部分。
1916900543&99702&MINIK_CLIENT_SONG_PLAY_OPERATE_REQ&{"songid": "LX_M012893", "mid": 99702, "optrate_type": 1, "uid": 49915635, "consume_type": 0, "play_time": 201, "dur_time": 272, "session_id": 14089, "songname": "那女孩对我说", "pkg_id": 4, "order_id": "InsertCoin_43347"}&3.0.1.15&2.4.4.30
xxxxxxxxxx//组织K,V格式的数据:(客户端请求类型,对应的json信息)val tableNameAndInfos:RDD[(String,String)] = clientLogInfos.map(line => line.split("&")) .filter(item => item.length == 6) .map(line => (line(2), line(3))) tableNameAndInfos.map(tp=>{...})将key为MINIK_CLIENT_SONG_PLAY_OPERATE_REQ的value从json中解析出来后形成如下格式:(key,songid+"\t"+mid+"\t"+optrateType+"\t"+uid+"\t"+consumeType+"\t"+durTime+"\t"+sessionId+"\t"+songName+"\t"+pkgId+"\t"+orderId)
key为其它值的保持原内容不变,并将tableNameAndInfos中的数据保存在HDFS文件系统的hdfs://mycluster/logdata/all_client_tables/${logDate}下,使用key作为文件名称。
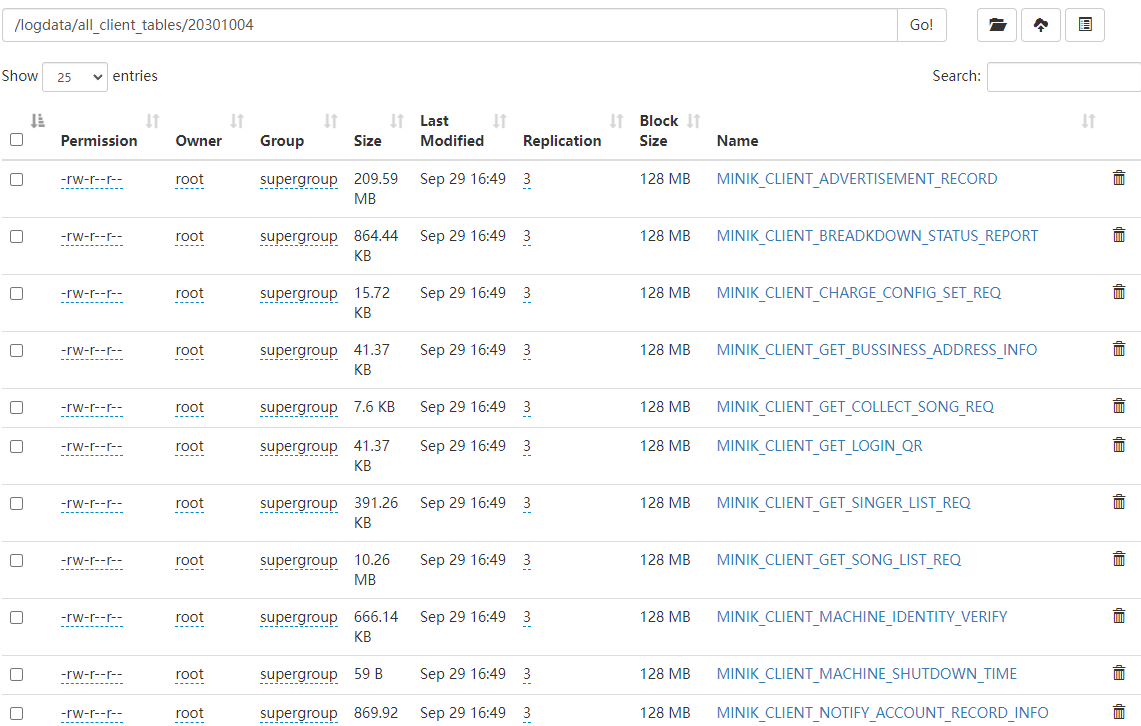
xxxxxxxxxx//转换数据,将数据分别以表名的方式存储在某个路径中tableNameAndInfos.map(tp=>{ val tableName = tp._1//客户端请求类型 val tableInfos = tp._2//请求的json string if("MINIK_CLIENT_SONG_PLAY_OPERATE_REQ".equals(tableName)){ val jsonObject: JSONObject = JSON.parseObject(tableInfos) val songid = jsonObject.getString("songid") //歌曲ID val mid = jsonObject.getString("mid") //机器ID //0:点歌, 1:切歌,2:歌曲开始播放,3:歌曲播放完成,4:录音试听开始, //5:录音试听切歌,6:录音试听完成 val optrateType = jsonObject.getString("optrate_type") //用户ID(无用户则为0) val uid = jsonObject.getString("uid") //消费类型:0免费;1付费 val consumeType = jsonObject.getString("consume_type") //总时长单位秒(operate_type:0时此值为0) val durTime = jsonObject.getString("dur_time") //局数ID val sessionId = jsonObject.getString("session_id") //歌曲名 val songName = jsonObject.getString("songname") //套餐ID类型 val pkgId = jsonObject.getString("pkg_id") //订单号 val orderId = jsonObject.getString("order_id") (tableName,songid+"\t"+mid+"\t"+optrateType+"\t"+uid+"\t"+consumeType+"\t"+durTime+"\t"+sessionId+"\t"+songName+"\t"+pkgId+"\t"+orderId) }else{ //将其他表的infos 信息直接以json格式保存到目录中 tp }}).saveAsHadoopFile( s"${hdfsclientlogpath}/all_client_tables/${logDate}", classOf[String], classOf[String], classOf[PairRDDMultipleTextOutputFormat])baizhan_musicxxxxxxxxxxsparkSession.sql(s"use $hiveDataBase ")xxxxxxxxxxsparkSession.sql( """ |CREATE EXTERNAL TABLE IF NOT EXISTS `TO_CLIENT_SONG_PLAY_OPERATE_REQ_D`( | `SONGID` string, --歌曲ID | `MID` string, --机器ID | `OPTRATE_TYPE` string, --操作类型 | `UID` string, --用户ID | `CONSUME_TYPE` string, --消费类型 | `DUR_TIME` string, --时长 | `SESSION_ID` string, --sessionID | `SONGNAME` string, --歌曲名称 | `PKG_ID` string, --套餐ID | `ORDER_ID` string --订单ID |) |partitioned by (data_dt string) |ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' |LOCATION 'hdfs://mycluster/user/hive_remote/warehouse/data/song/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D' """.stripMargin)'${hdfsclientlogpath}/all_client_tables/${logDate}/MINIK_CLIENT_SONG_PLAY_OPERATE_REQ'load到表TO_CLIENT_SONG_PLAY_OPERATE_REQ_D中(注意分区使用${logDate})xxxxxxxxxxsparkSession.sql( s""" | load data inpath | '${hdfsclientlogpath}/all_client_tables/${logDate}/MINIK_CLIENT_SONG_PLAY_OPERATE_REQ' | into table TO_CLIENT_SONG_PLAY_OPERATE_REQ_D partition (data_dt='${logDate}') """.stripMargin)println("**** all finished ****")