 目录
目录大数据全系列 教程
1869个小节阅读:465.1k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
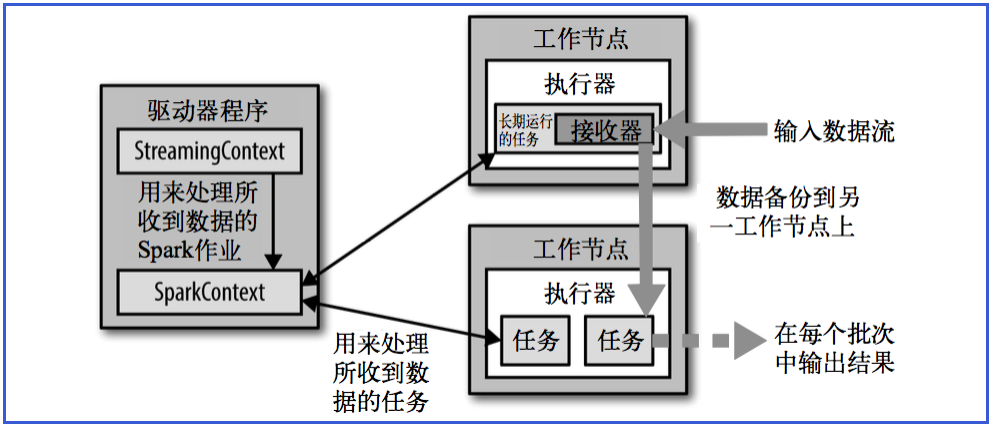
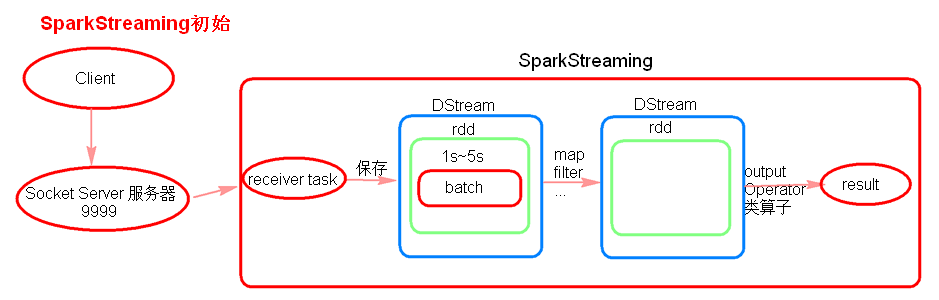
receiver task是7*24小时一直在执行,一直接收数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreaming将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6-9秒一边在接收数据一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作。
如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk如MEMORY_AND_DISK, 则内存存放不下的数据会溢写至硬盘, 加大延迟 )。
背压机制(了解)
Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure): 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
实时效果反馈
1. 关于SparkStreaming架构的描述,错误的是:
A 接收器(receiver task)是7*24小时一直在执行,一直接受数据。
B 如果job执行的时间大于batchInterval,接受过来的数据设置的存储级别是仅内存, 接收来的数据会越堆积越多,最后可能会导致OOM。
C 如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至硬盘,和只保存在 内存效率一样高 。
答案:
1=>C 设置StorageLevel包含disk, 则内存存放不下的数据会溢写至硬盘, 加大延迟 。