 目录
目录大数据全系列 教程
1869个小节阅读:468.1k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
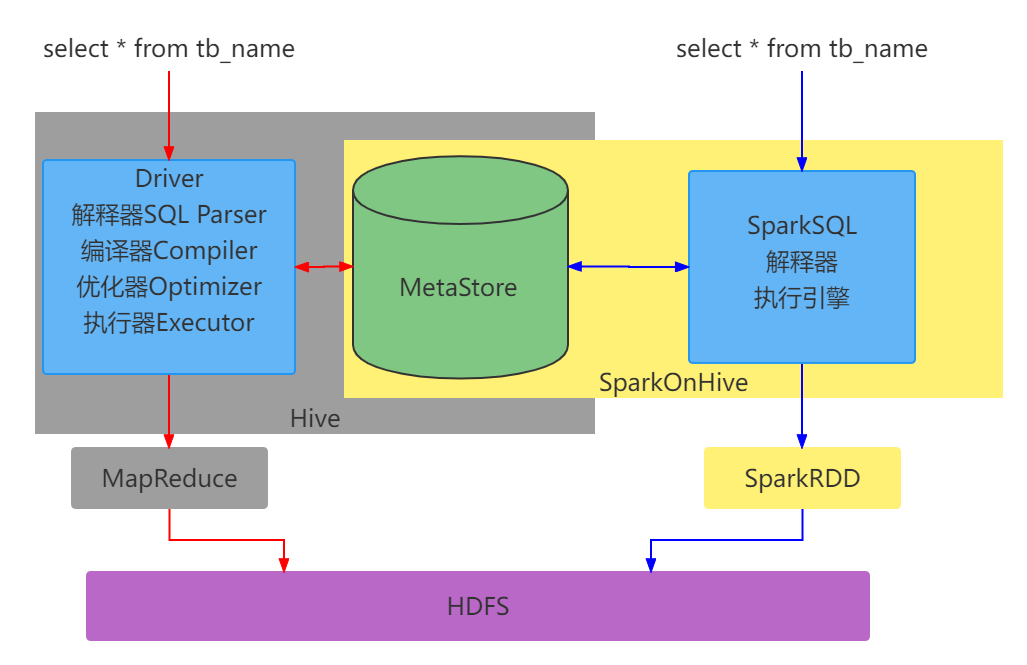
Spark On Hive
对于Spark来说,自身是一个执行引擎
。但是 Spark自己没有元数据管理功能,当我们执行∶
SELECT * FROM tb_score WHERE score> 60的时候,Spark完全有能力将SQL变成RDD提交。
但是问题是,tb_score 的数据在哪?tb_socre 有哪些字段? 字段啥类型? Spark完全不知道了 不知道这些东西,如何翻译RDD运行?
在SparkSQL代码中可以写SQL 那是因为,表是来自DataFrame注册的。DataFrame中有数据,有字段,有类型,足够Spark用来翻译RDD用。如果以不写代码的角度来看,
SELECT * FROM tb_score WHERE score> 60Spark无法翻译,因为没有元数据
。
解决方案
Spark提供执行引擎能力,Hive的MetaStore 提供元数据管理功能。 让Spark和Metastore连接起来,那么Spark On Hive 就有了∶
总结∶
Spark On Hive 就是把Hive的MetaStore服务拿过来 给Spark做元数据管理用而已。
市面上元数据管理的框架很多,为什么非要用Hive内置的MetaStore?
答案:Hive使用者众多,当然是为了收割Hive用户。
1. 关于Spark On Hive相关描述正确的是:
A Spark提供执行引擎能力。
B Hive的MetaStore提供元数据管理功能。
C Spark On Hive就是把Hive的MetaStore服务拿过来 给Spark做元数据管理用。
D 以上三个选项都正确
答案:
1=>D