 目录
目录大数据全系列 教程
1869个小节阅读:466.9k


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

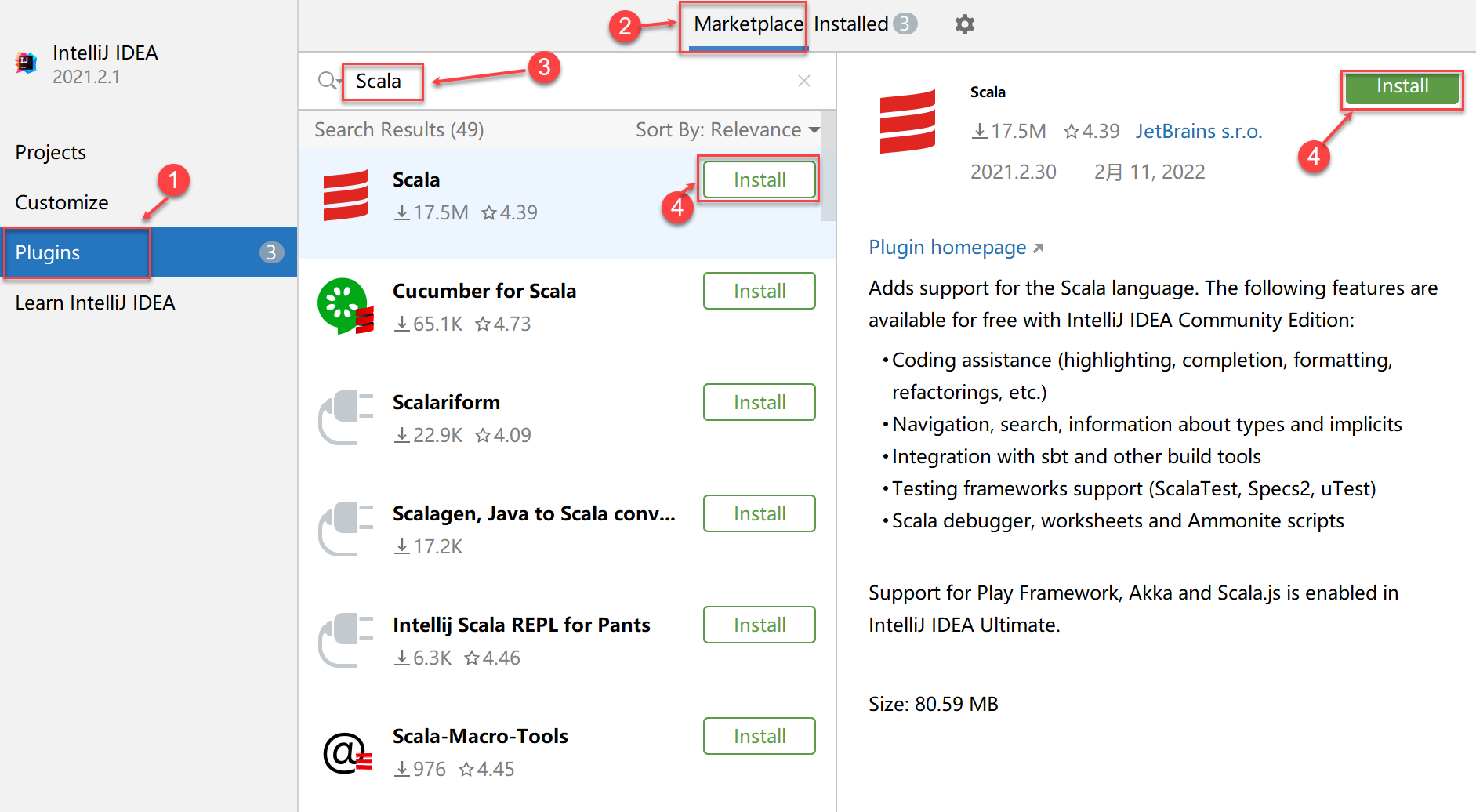
创建Maven项目sparkdemo(选择maven-archetype-quickstart)
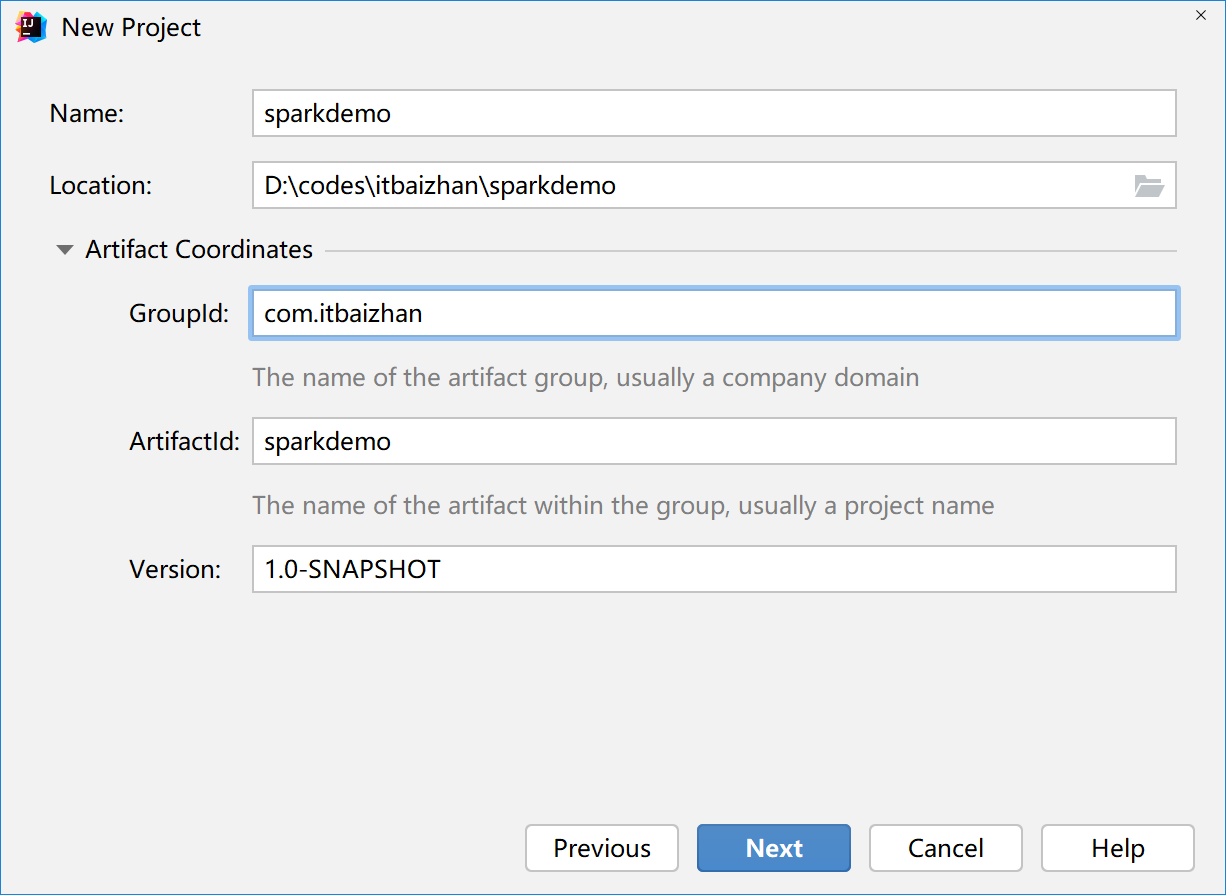
添加Scala支持
默认情况,IDEA中创建的Maven项目不支持Scala的开发,需要添加Scala语言的支持。
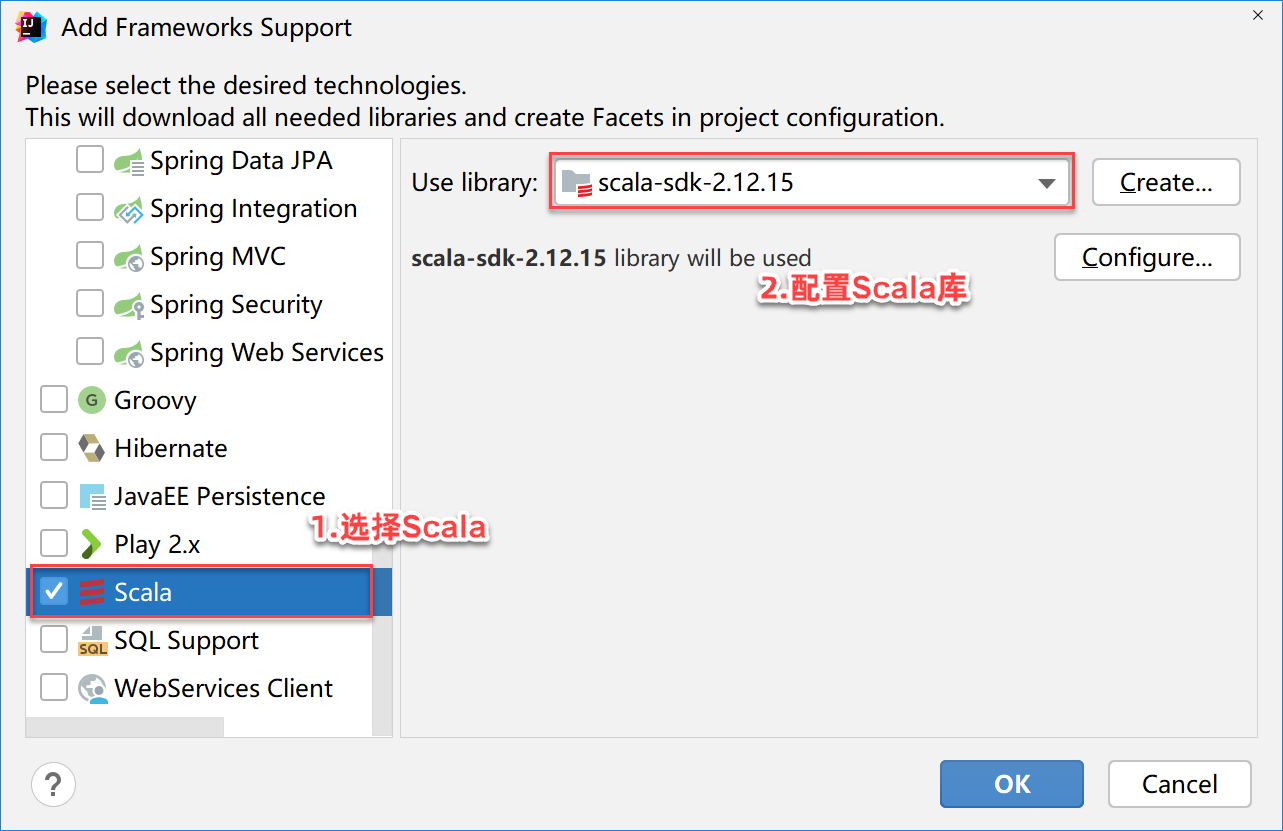
修改pom.xml文件添加Spark-core依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.2.1</version></dependency>在项目根目录下创建data目录,在data目录创建words.txt,添加如下内容
xxxxxxxxxxhello tomandy joyhello rosehello joymark andyhello tomandy rosehello joy
在src/main下面创建scala文件夹,并标注为Sources Root
选择scala文件夹右键创建Scala->com.itbaizhan.run.WordCount
xpackage com.itbaizhan//1.导入SparkConf,SparkContextimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}
object WordCount { def main(args: Array[String]): Unit = { //2.构建SparkConf对象,并设置本地运行和程序的名称 val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount") //3.通过SparkConf对象构建SparkContext对象 val sc = new SparkContext(conf) //4.读取文件,并生成RDD对象 val fileRdd: RDD[String] = sc.textFile("data/words.txt") //5.将单词进行切割,得到一个存储全部单词的集合对象 val wordsRdd: RDD[String] = fileRdd.flatMap(_.split(" ")) //6.将单词转换为Tuple2对象("hello"->("hello",1)) val wordAndOneRdd: RDD[(String, Int)] = wordsRdd.map((_, 1)) //7.将元祖的value按照key进行分组,并对该组所有的value进行聚合操作 val resultRdd: RDD[(String, Int)] = wordAndOneRdd.reduceByKey(_ + _) //8.通过collect方法收集RDD数据 val wordCount: Array[(String, Int)] = resultRdd.collect() //9.输出结果 wordCount.foreach(println) }}
xxxxxxxxxx# Set everything to be logged to the consolelog4j.rootCategory=ERROR, consolelog4j.appender.console=org.apache.log4j.ConsoleAppenderlog4j.appender.console.target=System.errlog4j.appender.console.layout=org.apache.log4j.PatternLayoutlog4j.appender.console.layout.ConversionPattern=%d{MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell/spark-sql log level to WARN. When running the# spark-shell/spark-sql, the log level for these classes is used to overwrite# the root logger's log level, so that the user can have different defaults# for the shell and regular Spark apps.log4j.logger.org.apache.spark.repl.Main=WARNlog4j.logger.org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver=WARN
# Settings to quiet third party logs that are too verboselog4j.logger.org.sparkproject.jetty=WARNlog4j.logger.org.sparkproject.jetty.util.component.AbstractLifeCycle=ERRORlog4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFOlog4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFOlog4j.logger.org.apache.parquet=ERRORlog4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive supportlog4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATALlog4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
# For deploying Spark ThriftServer# SPARK-34128:Suppress undesirable TTransportException warnings involved in THRIFT-4805log4j.appender.console.filter.1=org.apache.log4j.varia.StringMatchFilterlog4j.appender.console.filter.1.StringToMatch=Thrift error occurred during processing of messagelog4j.appender.console.filter.1.AcceptOnMatch=false
xxxxxxxxxx(tom,2)(andy,3)(hello,5)(joy,3)(rose,2)(mark,1)