 目录
目录大数据全系列 教程
1869个小节阅读:467.9k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

1. 萌芽阶段(1978~1988年)。
数据仓库概念最早可追溯到20世纪70年代,MIT(麻省理工)的研究员致力于研究一种优化的技术架构,该架构试图将业务处理系统和分析系统分开,即将业务处理和分析处理分为不同层次,针对各自的特点采取不同的架构设计原则,MIT的研究员认为这两种信息处理的方式具有显著差别,以至于必须采取完全不同的架构和设计方法。但受限于当时的信息处理能力,这个研究仅仅停留在理论层面。
2. 探索阶段。
20世纪80年代中后期,DEC公司(美国数字设备公司)结合MIT的研究结论,建立了TA2(Technical Architecture2)规范,该规范定义了分析系统的四个组成部分:数据获取、数据访问、目录和用户服务。其中的数据获取和数据访问目前大家都很清楚,而目录服务是用于帮助用户在网络中找到他们想要的信息,类似于业务元数据管理;用户服务用以支持对数据的直接交互,包含了其他服务的所有人机交互界面,这是系统架构的一次重大转变,第一次明确提出分析系统架构并将其运用于实践。
3. 雏形阶段(1988年)
1988年,为解决全企业集成问题,IBM公司第一次提出了信息仓库(InformationWarehouse)的概念:“一个结构化的环境,能支持最终用户管理其全部的业务,并支持信息技术部门保证数据质量”,并称之为VITAL规范(VirtuallyIntegrated Technical Architecture Lifecycle)。并定义了85种信息仓库的组件,包括数据抽取、转换、有效性验证、加载、Cube开发和图形化查询工具等。至此,数据仓库的基本原理、技术架构以及分析系统的主要原则都已确定,数据仓库初具雏形。
4. 确立阶段(1991年)
1991年,比尔·恩门(Bill Inmon)出版了他的第一本关于数据仓库的书《Building the Data Warehouse》,标志着数据仓库概念的确立。该书定义了数据仓库非常具体的原则,包括:
这些原则到现在仍然是指导数据仓库建设的最基本原则。凭借着这本书,比尔·恩门(Bill Inmon)被称为“数据仓库之父”。

比尔·恩门主张自上而下的建设企业级数据仓库EDW (Enterprise Data Warehouse),认为数据仓库是一个整体的商业智能系统的一部分, 一家企业只有一个数据仓库,数据集市(数据集市中存储为特定用户需求而预先计算好的数据,从而满足用户对性能的需求)的信息来源出自数据仓库,在数据仓库中,信息存储符合第三范式,大致结构如下:
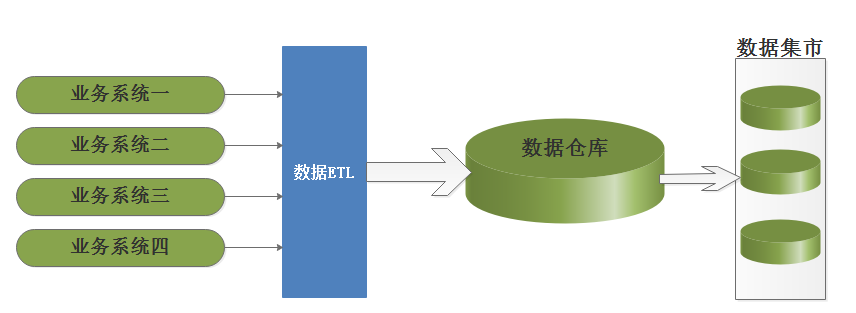
由于企业级数据仓库的设计、实施很困难,使得最早吃数据仓库螃蟹的公司遭到大面积的失败,除了常见的业务需求定义不清、项目执行不力之外,很重要的原因是因为其数据模型设计,在企业级数据仓库中,比尔·恩门(Bill Inmon)推荐采用3范式进行数据建模,但是不排除其他的方法,但是比尔·恩门的追随者固守OLTP系统的3范式设计,从而无法支持决策支持(DSS -Decision Suport System )系统的性能和数据易访问性的要求。
1994年前后,实施数据仓库的公司大都以失败告终,这时,拉尔夫·金博尔(Ralph Kimball)出现了,他的第一本书《The DataWarehouse Toolkit》掀起了数据集市的狂潮,这本书提供了如何为分析进行数据模型优化详细指导意见。

拉尔夫·金博尔主张自下而上的建立数据仓库,极力推崇建立数据集市,认为数据仓库是企业内所有数据集市的集合,信息总是被存储在多维模型当中,为传统的关系型数据模型和多维OLAP之间建立了很好的桥梁,其思路如下:
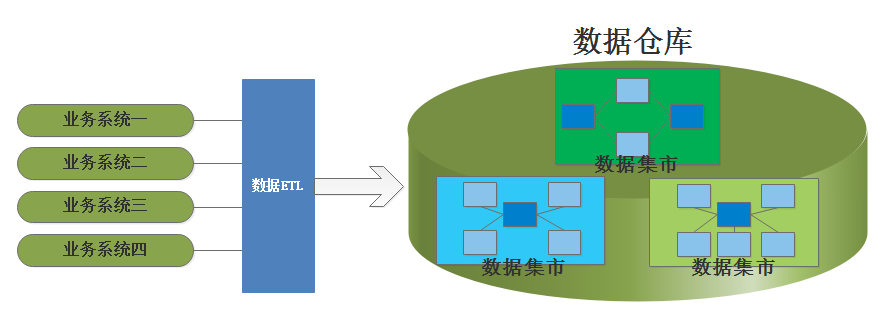
5. 争吵与混乱(1996-1997年)
Bill Inmon(比尔·恩门)的《Building the Data Warehouse》主张建立数据仓库时采用自上而下 方式,以第3范式进行数据仓库模型设计,而Ralph Kimball(拉尔夫·金博尔)在《The DataWarehouse Toolkit》则是主张自下而上的方式,力推数据集市建设。企业级数据仓库还是部门级数据集市?关系型还是多维?比尔·恩门 和拉尔夫·金博尔一开始就争论不休,其各自的追随者也唇舌相向,形成相对立的两派:Inmon派和Kimball派。
在初期,数据集市的快速实施和较高的成功率让Kimball派占了上风,由于数据集市仅仅是数据仓库的某一部分,实施难度大大降低,并且能够满足公司内部部分业务部门的迫切需求,在初期获得了较大成功。但是很快,他们也发现自己陷入了某种困境:随着数据集市的不断增多,这种架构的缺陷也逐步显现,公司内部独立建设的数据集市由于遵循不同的标准和建设原则,以致多个数据集市的数据混乱和不一致。解决问题的方法只能是回归到数据仓库最初的基本建设原则上来。
6. 合并(1998-2001年)
两种思路和观点在实际的操作中都很难成功的完成项目交付,1998年,比尔·恩门提出了新的BI架构CIF(Corporation information factory),把拉尔夫·金博尔的数据集市也包容进来。CIF的核心是将数仓架构划分为不同的层次以满足不同场景的需求,比如常见的ODS(操作数据层)、DW(数据仓库层)、DM(数据集市层)等,每层根据实际场景采用不同的建设方案,现在CIF已经成为建设数据仓库的框架指南,但自上而下还是自下而上的进行数据仓库建设,并未统一。
以上就是到目前为止,整体数仓建设来源的过程。