 目录
目录大数据全系列 教程
1869个小节阅读:467.2k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
##一、HBase概述、架构与搭建
HBase官网:http://hbase.apache.org/
Welcome to Apache HBase™
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Apache HBase™是Hadoop数据库,是一个分布式、可伸缩、大数据存储区。
当您需要随机、实时读/写访问大数据时,请使用Apache HBase™。 该项目的目标是在商用硬件集群之上托管非常大的表----数十亿行X百万列。 Apache HBase是一个开源的、分布式的、版本化的、非关系的数据库,它参考了Google的Bigtable。 正如Bigtable利用Google文件系统提供的分布式数据存储一样,Apache HBase在Hadoop的HDFS之上提供了类似Bigtable的功能。
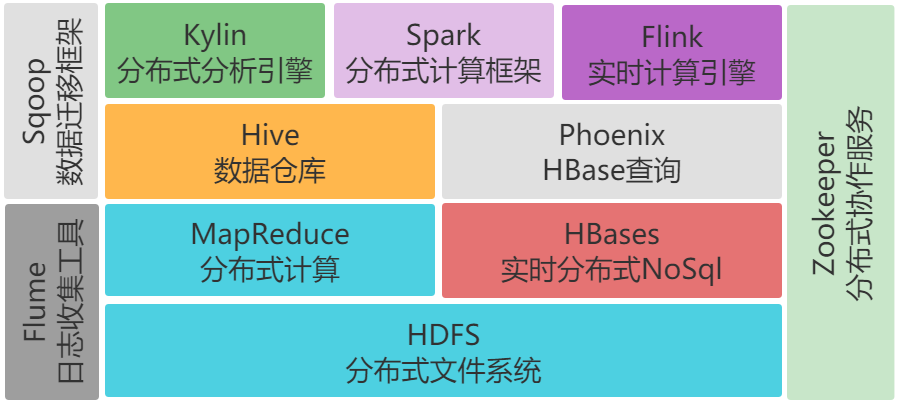
定义:HBase是Hadoop Database,是一个高可靠性、高性能、面向列族、可伸缩、实时读写的分布式NOSQL数据库。
作用:主要用来存储非结构化、半结构化和结构化的松散数据(列式存储的NoSQL 数据库)
利用Hadoop HDFS作为其文件存储系统,利用Zookeeper作为其分布式协同服务。正常情况下,HBase不依赖于YARN,用到的时候可以随时开启。从技术上讲,HBase实际上更像是“数据存储”而不是“数据库”,因为它缺少RDBMS中的许多功能,例如字段类型,二级索引,触发器和高级查询语言等。
MySQL亿级别的数据,效率极具下降。常见的解决方案为分库分表,然而它有存在如下问题。
tb_order达到10亿条数据,是不是非常慢呢?HBase出现之前互联网公司又是如何解决的呢?
一家互联网公司面对“伸缩性”这个问题,最好的选择是使用一个 MySQL 集群。维护一个几十乃至上百台服务器的 MySQL 集群是可行的,但是,如果要像 GFS 一样到一千乃至数千台服务器,还有可行性吗?下面我们就一起来看一下。
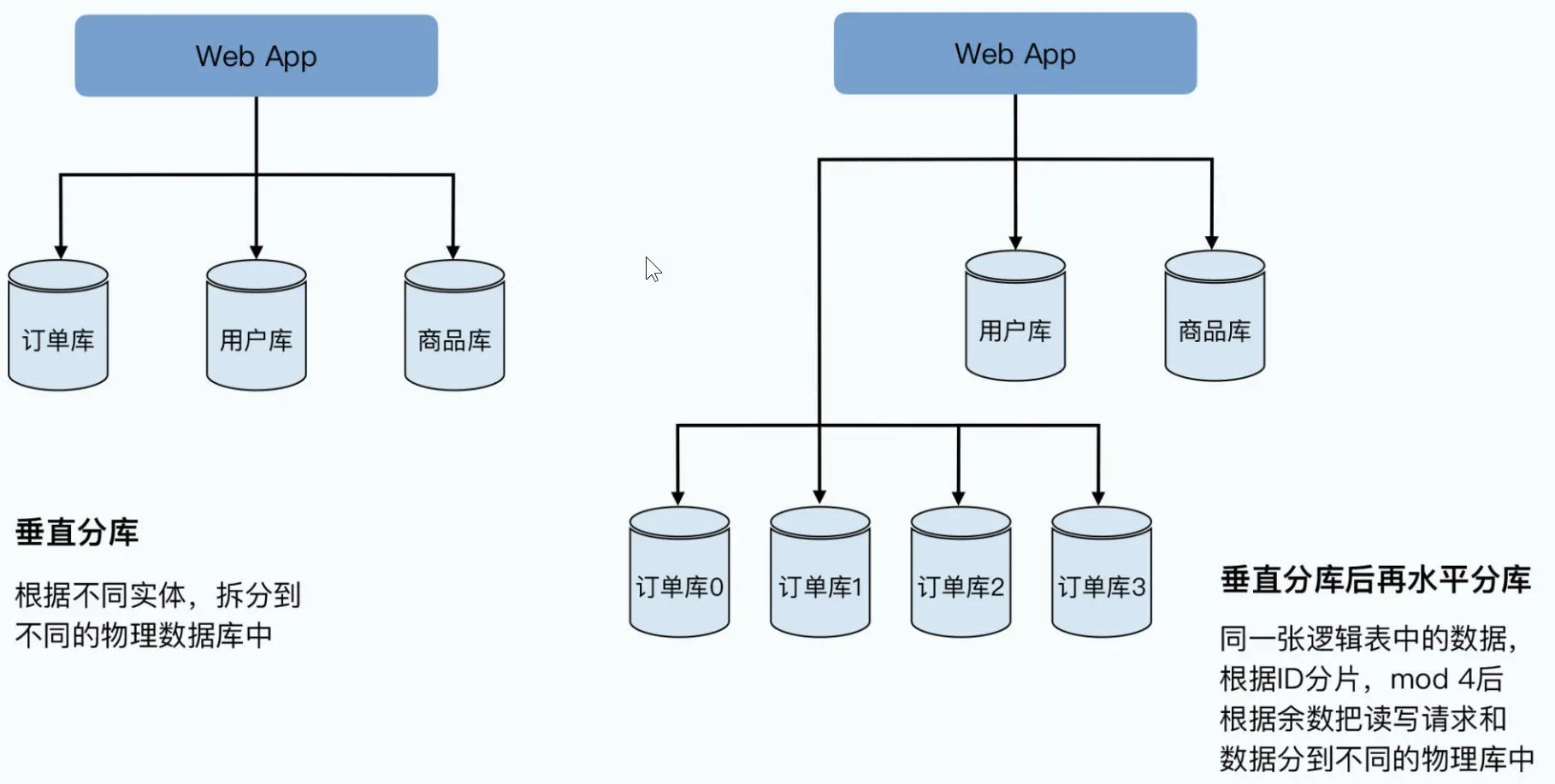
分库分表的扩容方式一致性的随机读写,在单个服务器上似乎并不是什么问题。如果你用过 MySQL 这样的数据库,你可以很容易地通过简单的 SQL,完成增删改查这样的随机数据读写。如果要把单机的 MySQL 扩展成分布式,好像也不是什么难题,只要做个分库分表就好了,这些套路你应该听说过。
一般来说,我们会先做垂直分库,在电商的系统里,我们把用户、商品、订单的表拆分到不同服务器的数据库上。如果发现这样还不行,我们就再进行水平分库,把订单号 Hash 一下,然后取“模”(mod)个 4,拆分到 4 台不同的服务器的数据库里。这样,每台机器只需要承接 1/4 的负担,看起来这种方式也能解决问题。当然,在分库分表的过程中,我们已经放弃了 MySQL 这样的关系型数据库的很多特性,比如外键关联这样的约束,以及单个数据库里面的跨行跨表的事务。
那么,为什么谷歌还需要发明一个 Bigtable,以及HBase 呢?这是因为分库分表,并不是一个很好的实现“可伸缩性”和“可运维性”的方案。基于分库分表的方案,运维起来会很费劲,主要体现在以下三点。
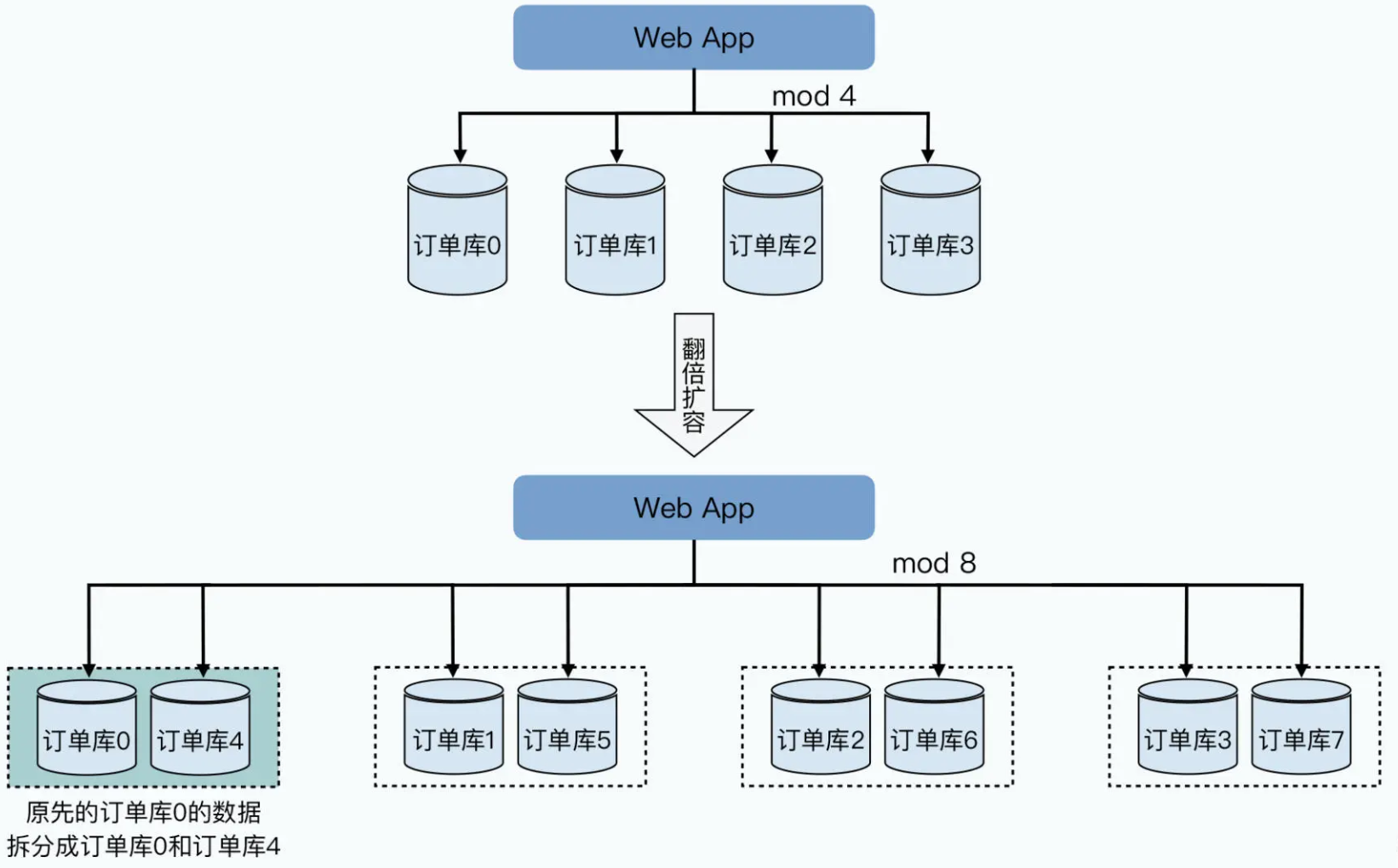
不得不进行的“翻倍扩容”
首先,是资源使用很浪费。当服务器性能出现瓶颈需要扩容的时候,我们常常只能采取“翻倍”分库增加服务器的方案。就以前面举的订单表为例,我们通过把订单号“模”上个 4,拆分到 4 个不同的服务器的数据库里。而随着我们承接的订单越来越多,每天 SQL 查询的请求越来越多,服务器的峰值 CPU 可能超过了 60%。为了安全起见,我们希望对服务器进行扩容,让峰值 CPU 控制在 40% 以下。但是这个时候,我们没办法只是增加 4 * 0.6 / 0.4 - 4 = 2 台服务器,而是不得不“翻倍”增加 4 台服务器。
数据分区进行解决
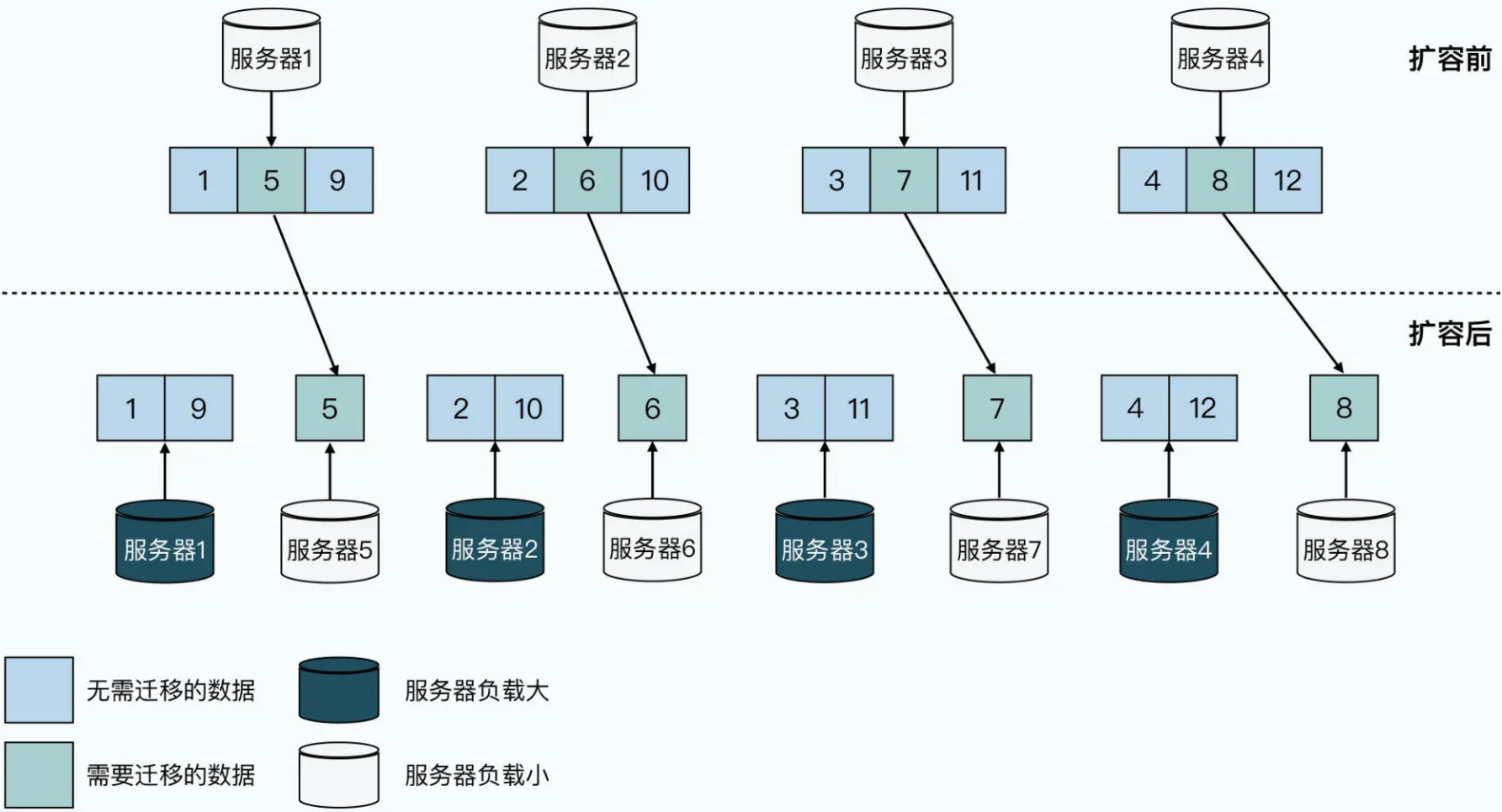
在扩容之后,服务器 1 无论是数据量,还是日常读写的负载,都比服务器 5 要高上一倍。使用 MySQL 集群,需要你在一开始就对如何切分数据做好精心设计。一旦稍有不慎,设计上出现了数据倾斜,就很容易造成服务器忙得忙死,闲得闲死的现象。并且即使你已经考虑得非常仔细了,随着业务本身的变化,比如要搞个双十一,也会把你一朝打回原形。
天天跑机房的人肉运维。
最后,是故障恢复需要人工介入。在 MySQL 集群里,我们可以对每个服务器都准备一个高可用的备份,避免一出现故障整个集群就没法用了。但是此时,我们的运维人员仍然需要立刻介入,因为这个时候系统是多了一个“单点”的,我们需要手工添加一台新的服务器进入集群,同步到最新的数据。
实时反馈
1. 关于MySQL分库分表的方案相关描述,错误的是:
A 当服务器性能出现瓶颈需要扩容时,常常采取“翻倍”分库增加服务器的方案,导致资源的浪费。
B 一开始就对如何切分数据做好精心设计,一旦稍有不慎,设计上出现了数据倾斜。
C 故障恢复需要不需要人工介入,运维简单。
2. 关于HBase的描述,错误的是:
A HBase是一个开源的、分布式的、版本化的、非关系的数据库,它参考了Google的Bigtable。
B HBase™是Hadoop数据库,是一个分布式、可伸缩、大数据存储区。
C 目标是在商用硬件集群之上托管非常大的表----数十亿行X百万列。
D 只能用来存储结构化的数据
答案:
1.C 2.D