 目录
目录大数据全系列 教程
1869个小节阅读:465.8k
目录


408考研
JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
分区提供一个通过目录隔离数据和查询优化的的遍历方式,不过不是所有的数据集都能形参合理的分区。对于一张表或这分区,可以进一步形参分桶,相比于分区分桶是个更小粒度的数据范围的划分。
分桶表是对列值取哈希值取模的方式,将不同数据放到不同文件中存储;由列的哈希值除以桶的个数得到的余数来决定每条数据划分在哪个桶中。
分区的本质是分目录,分桶的本质是分文件。
适用场景:
数据抽样( sampling )
关联查询
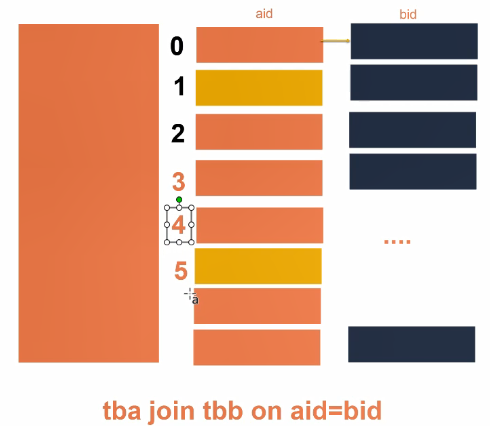
mr运行时会根据bucket的个数自动分配reduce task个数。(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶数(文件数量)和reduce task个数一致。
建表脚本:
xxxxxxxxxxCREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] 创建分桶表:
xxxxxxxxxxcreate table psnbucket( id int, name string, age int)clustered by (age) into 4 buckets row format delimited fields terminated by ',';创建原始数据表:
xxxxxxxxxxcreate table psn31( id int, name string, age int)row format delimited fields terminated by ',';准备测试数据:
xxxxxxxxxx[root@node4 data]# vim bucket1,tom,112,cat,223,dog,334,hive,445,hbase,556,mr,667,alice,778,scala,88将数据给添加到psn31表中:
xxxxxxxxxxhive> load data local inpath '/root/data/bucket' into table psn31;Loading data to table default.psn31OKTime taken: 1.656 secondshive> select * from psn31;OKpsn31.id psn31.name psn31.age1 tom 112 cat 223 dog 334 hive 445 hbase 556 mr 667 alice 778 scala 88Time taken: 3.263 seconds, Fetched: 8 row(s)将psn31中的数据导入到psnbucket中
xxxxxxxxxxhive> insert into table psnbucket select id,name,age from psn31;Query ID = root_20211119125326_ea57ba42-a38f-43d9-9c78-b9ce17d7cf4dTotal jobs = 2Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 44个桶对应四个reduce任务数。
查看结果文件列表:
xxxxxxxxxx[root@node4 data]# hdfs dfs -ls /user/hive_remote/warehouse/psnbucketFound 4 items-rw-r--r-- 3 root supergroup 21 2021-11-19 12:55 /user/hive_remote/warehouse/psnbucket/000000_0-rw-r--r-- 3 root supergroup 20 2021-11-19 12:54 /user/hive_remote/warehouse/psnbucket/000001_0-rw-r--r-- 3 root supergroup 17 2021-11-19 12:54 /user/hive_remote/warehouse/psnbucket/000002_0-rw-r--r-- 3 root supergroup 20 2021-11-19 12:55 /user/hive_remote/warehouse/psnbucket/000003_0查看文件中的内容:
xxxxxxxxxx[root@node4 data]# hdfs dfs -cat /user/hive_remote/warehouse/psnbucket/000000_08,scala,884,hive,44[root@node4 data]# hdfs dfs -cat /user/hive_remote/warehouse/psnbucket/000001_07,alice,773,dog,33[root@node4 data]# hdfs dfs -cat /user/hive_remote/warehouse/psnbucket/000002_06,mr,662,cat,22[root@node4 data]# hdfs dfs -cat /user/hive_remote/warehouse/psnbucket/000003_05,hbase,551,tom,11