 目录
目录大数据全系列 教程
1869个小节阅读:464.9k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night

UDAF:用户自定义聚合函数。强类型的Dataset和弱类型的DataFrame都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。通过继承UserDefinedAggregateFunction来实现用户自定义弱类型聚合函数。从Spark3.0版本后,UserDefinedAggregateFunction已经不推荐使用了。可以统一采用强类型聚合函数Aggregator。
UDAF原理图
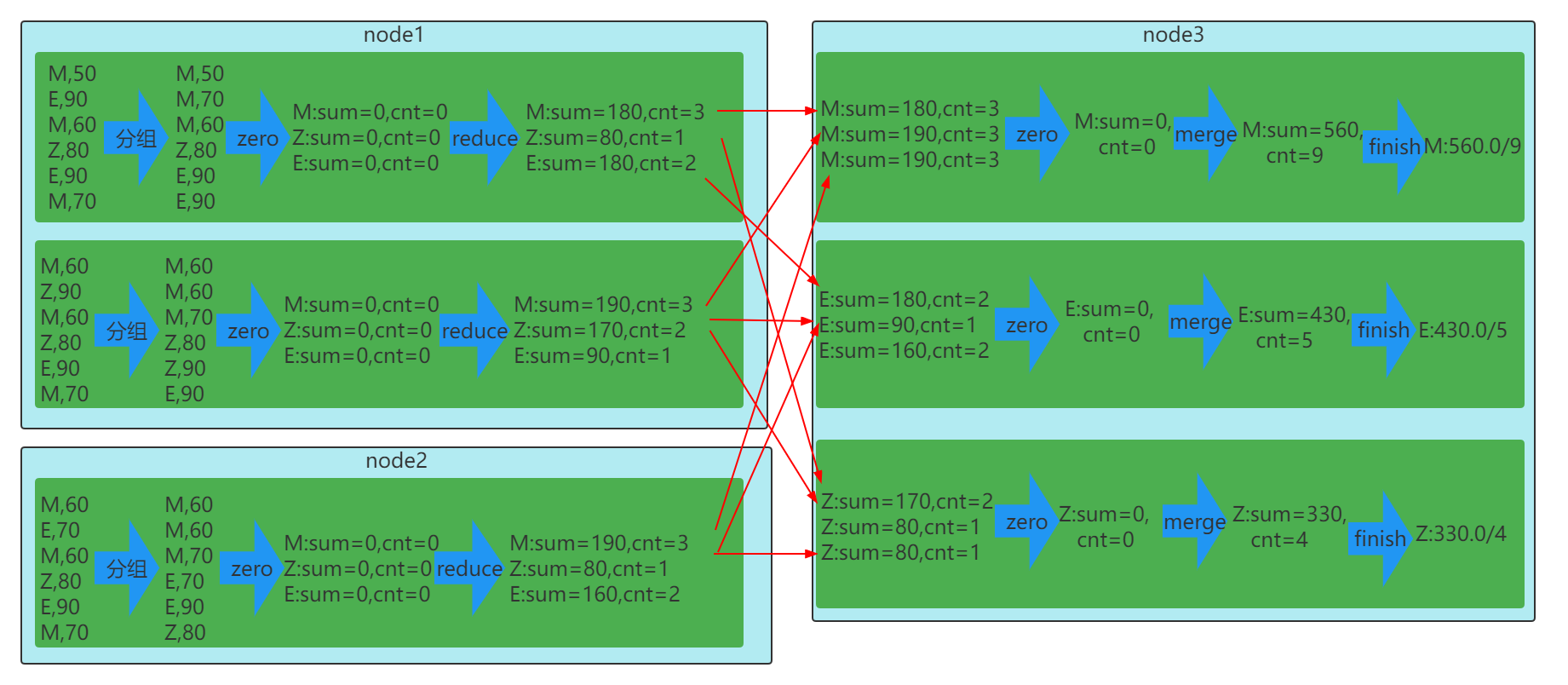
xxxxxxxxxxpackage com.itbaizhan.sql.deffun
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}import org.apache.spark.sql.types.{DataType, IntegerType, StringType, StructField, StructType}import org.apache.spark.sql.{DataFrame, Encoder, Encoders, Row, SparkSession, functions}
/**SparkSQL UDAF:User Defined Aggregate Function * 用户自定义的聚合函数 * 1.自定义类需要继承Aggregate类,并重写抽象方法 * 2.明白UDAF的执行原理 * 3.掌握如何重写这些抽象方法 */object UserDefUDAFNew { def main(args: Array[String]): Unit = { //1.创建SparkSession对象 val spark: SparkSession = SparkSession.builder() .master("local[*]") .appName("udafNew") .getOrCreate() //3.读取json文件 val df: DataFrame = spark.read.json("data/sql/score.json") //4.注册临时视图 df.createOrReplaceTempView("tb_score") //5.注册自定义UDAF函数 spark.udf.register("my_avg",functions.udaf(new MyUDAF())) //6.调用自定义的udaf函数查询每个科目,以及该科目的平均分 spark.sql( """ |select project,my_avg(score) avg_score |from tb_score |group by project |""".stripMargin).show() //2.关闭 spark.close() }}//自定义样例类case class MyBuf(var sum:Int,var cnt:Int)//自定义类MyUDAFclass MyUDAF extends Aggregator[Int,MyBuf,Double]{ //赋初始化的值 0,0 override def zero: MyBuf = MyBuf(0,0) //map端将每个分区下同一组数据进行聚合操作 override def reduce(b: MyBuf, a: Int): MyBuf = { b.sum += a b.cnt += 1 b } //reduce端将同一个分组的数据进行聚合 override def merge(b1: MyBuf, b2: MyBuf): MyBuf = { b1.sum += b2.sum b1.cnt += b2.cnt b1 } //聚合后每组数据得到一个MyBuf对象,然后[再做最后的计算]并返回结果 override def finish(reduction: MyBuf): Double = reduction.sum.toDouble/reduction.cnt //中间结果的序列化,元祖或样例类调用Encoders.product进行序列化 override def bufferEncoder: Encoder[MyBuf] = Encoders.product //最终结果的序列化 override def outputEncoder: Encoder[Double] = Encoders.scalaDouble}输出结果:
xxxxxxxxxx+-------+-----------------+|project| avg_score|+-------+-----------------+| E|89.33333333333333|| M|89.33333333333333|| Z| 84.0|+-------+-----------------+