 目录
目录大数据全系列 教程
1869个小节阅读:464.7k
目录


JAVA全系列 教程
面向对象的程序设计语言
Python全系列 教程
Python3.x版本,未来主流的版本
人工智能 教程
顺势而为,AI创新未来
大厂算法 教程
算法,程序员自我提升必经之路
C++ 教程
一门通用计算机编程语言
微服务 教程
目前业界流行的框架组合
web前端全系列 教程
通向WEB技术世界的钥匙
大数据全系列 教程
站在云端操控万千数据
AIGC全能工具班

A A
White Night
#八、读写流程(重点)
###8.1.1 写文件流程剖析

三大角色:HDFS client、NameNode、DataNode。写文件过程中涉及到这三个角色之间联动。
调用客户端的对象DistributedFileSystem的create方法:create(new Path("/user/hh.txt"));
DistributedFileSystem会发起对namenode的一个RPC连接,请求创建一个文件,不包含关于block块的请求。namenode会执行各种各样的检查,判断客户端是否拥有有创建文件的权限,如果检查通过,namenode会创建一个文件(在edits中,同时更新内存状态),否则创建失败,客户端抛异常IOException,流程结束。hadoop2.x版本中如果指定的文件在对应的路径下已经存在,则创建失败;不存在则创建成功。hadoop3.1.3版本中如果指定的文件在对应的路径下已经存在,则覆盖。
NN在文件(空文件)创建后,返回给HDFSClient可以开始上传文件块。
xxxxxxxxxxFSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/user/hh.txt"));DistributedFileSystem返回一个FSDataOutputStream对象给客户端用于写数据。FSDataOutputStream封装了一个DFSOutputStream对象负责客户端跟datanode以及namenode的通信。
DFSOutputStream对象向NameNode请求上传文件块(比如:0-128M),让NN返回DataNode节点列表。
NN根据网络距离的远近和资源的使用情况来选择DN节点,并返回最适合的“三个”节点。
DFSOutputStream对象收到DN列表后,按照一定规则请求建立一个通道DN1->DN2->DN3
DN开启应答DN3->DN2->DN1->DFSOutputStream对象,至此双工通道建立完成。
DFSOutputStream对象将数据切分为小的数据包(64kb,core-default.xml:file.client-write-packet-size默认值65536),并写入到一个内部队列(“数据队列”)。DataStreamer会读取其中内容,DataStreamer将数据包发送给管线中的DN1,DN1将接收到的数据发送给DN2,DN2发送给DN3
DFSOoutputStream维护着一个数据包的队列,这的数据包是需要写入到datanode中的,该队列称为确认队列。当一个数据包在管线中所有datanode中写入完成,就从ack队列中移除该数据包。
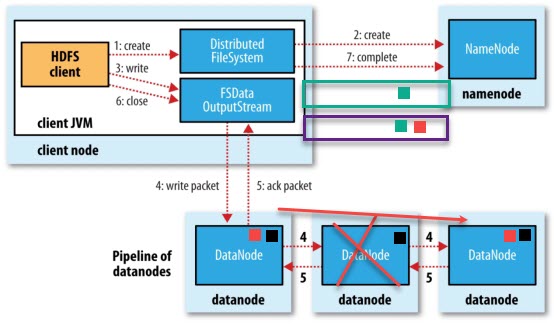
如果在数据写入期间datanode发生故障,则执行以下操作:
a) 关闭管线,把确认队列中的所有包都添加回数据队列的最前端,以保证故障节点下游的datanode不会漏掉任何一个数据包。
b) 为存储在另一正常datanode的当前数据块指定一个新的标志,并将该标志传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。
c) 从管线中删除故障数据节点并且把余下的数据块写入管线中另外两个正常的datanode。namenode在检测到副本数量不足时,会在另一个节点上创建新的副本。
d) 后续的数据块继续正常接受处理。
e) 在一个块被写入期间可能会有多个datanode同时发生故障,但非常少见。只要设置了dfs.replication.min的副本数(默认为1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标副本数(dfs.replication默认值为3)。
如果有多个block,则会反复从步骤3开始执行。
当客户端完成了所有的数据块的传输,调用数据流的close方法。该方法将数据队列中的剩余数据包写到DN的管线并等待管线的确认
客户端收到管线中所有正常DN的确认消息后,通知NN文件写完了。
namenode已经知道文件由哪些块组成,所以它在返回成功前只需要等待数据块进行最小量的复制。